Chapter 2
The organisation of information in the Directory
2.1 INTRODUCTION
This chapter looks at the models of the information that is held in the
Directory. The Directory as a whole is quite complex, and difficult to
understand. As an aid to understanding what the information looks like,
and how it is distributed and managed, various models are described in
the Standard. Each model presents a simplified view of just one aspect
of the Directory information. This makes it easier to understand, since
we only need to grapple with the concepts of one model at a time. We can
then try to link the models together in our mind, in order to get a clearer
picture of the Directory as a whole.
One model gives a view of the Directory information, as it is seen by
a typical user. (This was, in fact, the only information model described
in the '88 edition of the Standard.) This model, the Directory User Information
Model, simply called the Directory Information Model in the '88 Standard,
does not recognise that the Directory is distributed. From its perspective,
there is a large amount of information held in the Directory, and users
can access all of it, providing that they have the appropriate access rights.
To enable the correct information to be accessed, the users need a way
of identifying the items they want. Consequently, chunks of information
are given globally unambiguous names. The way in which Directory information
is identified, or named, is described in this model. The model is sufficiently
general to allow any sort of information to be held in the Directory, and
the Standard does not mandate what should be held there. However, if implementations
of X.500 are to be globally, or simply widely, accessible, then it is necessary
to have a subset of this information internationally standardised, so that
implementations from Mongolia to Massachusetts can understand it. The Standard
does therefore define a subset of the types of user information that can
be held in the Directory, in order to aid the international use of X.500.
The user information needs to be managed and administered by local administrators.
Human administrators will need to store management information in the Directory,
that controls aspects of the user information. Examples of these controls
are: the sort of user information that can be stored in this part of the
Directory, and who can access it. The Directory Operational and Administrative
Information Model provides the 'administrator's view' of the information
stored in the Directory. Administrators 'see' that there is more information
stored in the Directory, than do typical users. This model still presents
the Directory as a global information base, and the distribution of the
information between computer systems is not visible to the model. A certain
amount of the administrative information is defined in the Standard. This
is regarded as the minimum needed for administrators to manage their portion
of the Directory information, in an open environment. Specific implementations
may provide administrators with additional non-standard control information.
This is not restricted by the Standard.
The Directory User Information Model, and the Directory Operational
and Administrative Information Model, collectively make up the Directory
Information Models. Directory Information, refers to the Directory from
a (single) global perspective, and distribution of the information between
computer systems is not relevant. In other words, the Directory information
is viewed as if it were held in a single centralised database.
Another model is concerned with how the information is distributed between
the different computer systems (DSAs § 4.1.2) that provide the Directory
service. This is the DSA Information Model. The DSA Information Model describes
a model of the information that needs to be held by a single computer system,
in order for it to co-operate with others in providing a service to users
of the Directory. It is a 'DSA's view' of the information stored in the
Directory. Some of this information will be User Information, some of it
will be Administrative Information, and some of it will be its own operational
information. As an example of the latter, a system will need to store information
about where other parts of the User Information are stored. In this way
a DSA can relate its bit of information to the global Directory information.
A global database obviously is not controlled by one central authority,
but rather by lots of independent authorities. The way in which the management
and administration of the global database is distributed between these
independent authorities is explained in the Directory Administrative Authority
Model. Each independent authority will be responsible for the information
stored in its area of the Directory. The way in which this authority may
be delegated to sub-authorities is explained. So is the way in which a
clean transition is made between two independent authorities. The Administrative
Authority Model is described in § 2.11.
2.2 OBJECTS AND ENTRIES
The complete set of all information held in the Directory is known as the
Directory Information Base (DIB). As described above, not all of
this information is visible to normal users of the Directory. Also, when
we talk about Directory information, we are not concerned with the distribution
of the information between different computer systems.
The DIB consists of entries, and these entries are related hierarchically
to each other. The precise form of this hierarchy is described in §
2.4 and § 2.5. Entries are the basic building blocks of the database.
In the Directory User Information Model, an entry holds information
about an object of interest to users of the Directory. These (Directory)
objects might typically be associated with, or be some facet of, real world
things such as information processing systems or telecommunications equipment
or people. So there can be a Directory entry for an X.400 Message Transfer
Agent (§ 10.2), and another one for the manager. However, it is very
important to note that Directory objects do not necessarily have a one-to-one
correspondence to real world things. This has typically caused a lot of
confusion to non-experts, many of whom assume that every entry in the Directory
contains all the relevant information about one real world thing. This
is not necessarily so. Directory objects, and hence entries, can have a
one-to-one correspondence with real world things, or can have a many-to-one
or one-to-many relationship with real world things. For example, a Directory
object/entry may be a mailing list containing the names of many real people
(one-to-many correspondence). Alternatively, a real person may be represented
in the Directory as both a residential person object/entry and an organisational
person object/entry (many-to-one correspondence). In the latter case, the
organisational person Directory entry would hold information that is relevant
to describing the person in their working environment, holding their office
room number, internal telephone extension number, electronic mail address,
and the department etc., the residential person Directory entry would describe
the person in their residential capacity, holding their home postal address
and home telephone number etc.
Objects that have similar characteristics are identified by their object
class. Every object entry in the Directory is a member of at least
one object class. So, for example, there is an 'organisational person'
object class for organisational person entries, and a 'residential person'
object class for residential person entries. Object classes are described
more fully in Chapter 3.
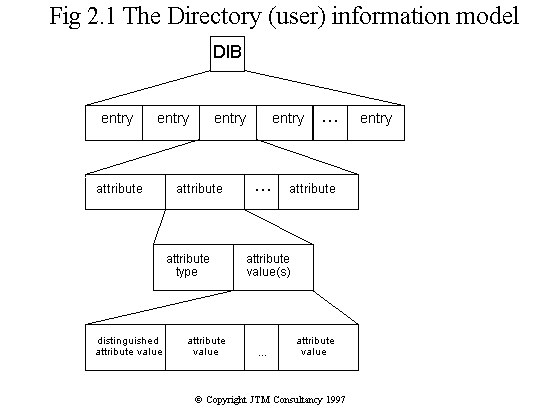
Fig. 2.1 The Directory (user) information model
2.3 ATTRIBUTES
Each piece of information that describes some aspect of an entry is called
an attribute. An attribute comprises an attribute type and
one or more attribute values. An example of an attribute type might
be 'telephone number' and an example of a telephone number attribute value
might be '+44 61 745 5000'. This is the extent of the information model
described in the '88 edition of the Standard, and this is shown pictorially
in Fig. 2.1. (The model also describes how entries are named, and the distinguished
attribute value will be described in § 2.4 and § 2.5.)
The Standard recognises that users (or their administrators, to be more
precise) of the Directory will want to define their own attribute types,
and that the number of different attribute types held in the Directory
will be almost boundless. However, there will be a set of attribute types
that are commonly usable by most, if not all, users of the Directory. It
would be sensible to standardise this set, so that different users in different
parts of the DIB are not referring to exactly the same type of information
but using different identifiers. Part 6 of the Standard defines a commonly
usable set of user attribute types, and a selection of these are shown
in Table 3.2.
2.4 THE STRUCTURE OF THE DIB
Entries held in the DIB are structured in a hierarchical manner, using
a tree structure, which is similar to a structure chart used by most hierarchical
organisations. The DIB can therefore be represented as a Directory Information
Tree (DIT), in which each node in the tree represents a Directory entry
(Fig. 2.2). Many entries have superior and subordinate entries, and these
are called non-leaf nodes or non-leaf entries. Entries which only have
superior entries, and no subordinate entries, are called leaf nodes or
leaf entries. At the apex of the DIT is the root entry, and this is the
only entry without a superior. (In an organisational chart it might be
the Managing Director or President who has no superior line manager.) Below
the root of the DIT there will typically be entries representing countries
or multinational organisations, and below these, entries representing organisations
and organisational units (divisions) respectively. (Below the President
or MD in an organisational structure chart might be vice-presidents or
divisional managers of functional areas such as sales and production, and
below these various line managers and other employees.) Minor differences
between an organisational structure chart and the DIT structure are in
how layers of the structure are constructed and named. It is recognised,
for example, that the root DIT entry will not actually exist in the real
world Directory (who will manage it?, who owns it?), whereas the Head of
an Organisation always exists! Consequently, users are not allowed to read
the root DIT entry, and it will not contain any user attributes. It only
occurs in the DIT model for completeness. Within an organisational structure
chart, each box is usually named with the role of the occupant, e.g. Chairman,
secretary, Northern Sales Manager, Requisition Clerk, and often contains
the name of the person currently occupying that position. The layer below
identifies the staff reporting to this person. In the DIT, each layer represents
objects contained in or associated with the superior node (e.g. organisations
are based in countries, and organisational units are contained within organisations).
The naming of the entries in the DIT takes a different form from that of
organisational structure charts, and this is described below.
Fig. 2.2 The structure of Directory entries
It will often be a relatively simple task to map an organisation's structure
into part of the DIT. However, organisations do not have to rigidly follow
their organisational structure when designing their DIT structure. They
may opt for a flatter structure in the DIT, so that browsers cannot determine
the structure of the organisation. Also, as described in § 8.6, access
controls can be used to prohibit browsers from discovering the structure
of an organisation's DIT subtree.
2.5 NAMING ENTRIES
Each object entry known to the Directory is distinguished from all other
objects by its name. Thus each entry is said to have a distinguished
name (DN). Each entry takes the name of its parent (or superior)
entry in the DIT, and has appended to this a relative distinguished
name (RDN). An entry's RDN uniquely identifies it from all of its peers
(Fig. 2.3). Since each RDN is guaranteed to be unique below any particular
non-leaf node, each entry is guaranteed to have a unique DN. There could
thus be an organisation called ACME Tools in the US, and a completely unrelated
company bearing the same name in the UK. Both would still have unique distinguished
names, since each is prefixed by a different country name.
A RDN is syntactically a set of attribute type and value pairs, enabling
an entry to have a multi-component RDN (as in Fig. 2.3 with the Sales unit
in Swindon). However, in the vast majority of real DIT entries to date,
RDNs usually only contain one attribute type and value pair. This is very
likely to continue to be the case. Only in exceptional circumstances will
administrators prefer or need to use more than one attribute value in a
RDN.
An entry's RDN is held in the entry along with all the other attributes.
Those attribute values which form part of the RDN are flagged as being
distinguished by the DSA software. This explains why Fig. 2.1 contains
a distinguished value box. However, users do not have to be told which
are the distinguished values, unless they have permission to read them
(Chapters 5 and 8). So it is not possible for a user to surreptitiously
determine the RDN of an entry from its attributes.
Note. Conforming '88 DSAs do have to return the
distinguished name of an entry, in reply to Read operations (and also to
Compare, List and Search if an alias name was used by the user). This restriction
has been dropped from the '93 version of the Standard.
The only entry allowed to have a null distinguished name and RDN is
the root entry. However, as stated before, it only occurs in the DIT model
for completeness.
2.6 ALIASES
It is often convenient for an object to be known by more than one name,
depending upon its role or referenced context. To allow for this, the concept
of aliases has been introduced into the Directory model of names. Each
Directory object only has one distinguished name, and therefore one entry
in the DIB, but it may have one or more alternate alias names (with corresponding
alias entries in the DIB). The name of an entry therefore only has to be
unambiguous, i.e. given the name you will get to precisely one entry
in the DIT, but it does not have to be unique, i.e. the only name
that will identify the entry.
Each alias name has a corresponding alias entry in the DIT. This contains
a pointer to the object entry, as shown in Fig. 2.4. (The pointer is actually
the name - in the '88 edition it has to be a distinguished name - of the
object entry which it points to. The pointer, like all other information,
is held as an attribute - the aliased object name attribute - of
the alias entry.) Alias entries have a special object class of alias (§
3.5), to distinguish them from object entries. All alias entries are leaf
entries in the DIT.
As a real life example, Salford University owns a business known as
Salford University Business Services (SUBS), which is an organisation registered
at Companies House in the UK. It has the distinguished name {Country =
GB, Organisation = Salford University Business Services Ltd}. However,
people may think that the business is a department within the University,
since it is located next to the university campus. Therefore, an alias
has been created below the University of Salford entry, with the (distinguished)
name {Country = GB, Organisation = Salford University, Organisational Unit
= Salford University Business Services}. This alias points to the real
Business Services entry in the DIT. Anyone referencing SUBS via the alias
name in the University will be automatically re-routed to the real Business
Services entry by the Directory, through a process termed alias dereferencing
(§ 2.7).
In the '88 edition of the Standard, an alias may not point to another
alias (w/w 2.2) but in the '93 edition of the Standard this restriction
has been dropped. The feature may be useful in the following situation.
A person moves between divisions within an organisation. The original distinguished
name is replaced by an alias which points to the new distinguished name
in the new division. The person is thus still contactable by either their
old or their new name. Suppose the person moves again within a very short
timescale (some organisations re-organise frequently!). A second alias
could be inserted into the DIT, replacing their previous 'new' name, and
pointing to their new 'new' name. The person can now be identified by all
three names. This second alias insertion is not allowed by the '88 edition
of the Standard.
2.7 PURPORTED NAMES, NAME RESOLUTION
AND ALIAS DEREFERENCING
A directory user will generally give a 'purported' name as input to a directory
query. A purported name is syntactically a name (i.e. a sequence of RDNs)
but it may or may not name an actual entry in the DIT. Name Resolution
is a procedure carried out by the Directory, which determines if the purported
name is valid, i.e. if it unambiguously identifies a single entry in the
DIT. Logically, name resolution is the process of sequentially matching
each RDN in a purported name to an arc in the DIT, beginning at the root
and working downwards in the DIT. If an alias is encountered, this is dereferenced
and name resolution recommences again from the root, with the name pointed
to in the alias entry.
For example, by reference to Fig. 2.4, suppose a user quoted the purported
name {C=GB, O=University of Salford, OU=Salford University Business Services,
OU=Software Services, CN=Dave Morgan}. Name resolution would start at the
root, and would eventually reach the alias entry {C=GB, O=University of
Salford, OU=Salford University Business Services}. Alias dereferencing
would replace that part of the purported name that had already been used,
by the 'aliased object name' value in the alias. The purported name would
thus become {C=GB, O=Salford University Business Service Ltd, OU=Software
Services, CN=Dave Morgan}. Name resolution would now start again from the
root, with this new name.
A description of how name resolution and alias dereferencing work in
the distributed directory, is given later in § 4.5, § 9.13.6
and Appendix B.
2.8 COLLECTIVE ATTRIBUTES
It was soon realised after 1988 that the above information model was too
simplistic. There need to be different types of information (attributes)
stored in the Directory. For example, some user attributes could apply
to a whole series of entries, e.g. all the employees of an organisation
may be contactable on the same telephone number, with a switchboard operator
locally routing the call to an internal extension number. It would be very
inefficient to have to repeat the organisation's telephone number attribute
in the entries of all the employees. Ideally, the telephone number should
be stored once in the Directory, along with an indication of the entries
to which it applies. Then when a user reads an employee's entry, to which
this shared attribute applies, it would be returned along with the other
user attributes of the entry. This new type of information is allowed in
the '93 edition of the Standard, and is called a collective attribute.
Collective attributes are a special type of user attribute, which have
the above properties. They are part of the '93 Directory User Information
Model. They are read from entries like other user attributes, but they
cannot be updated like them. This is because they are not actually stored
in the entry. They are stored in a special entry, called a subentry
(§ 2.12). Subentries are not visible in the User Information Model.
They are normally only visible to administrators. A subentry contains a
description of the DIT subtree of entries to which its collective attributes
apply. Using the example above, there could be a subentry associated with
the organisation's entry, which describes the complete subtree below the
organisation's entry. This subentry would hold the organisation's collective
'telephone number' attribute. This collective attribute would then apply
to all the entries of the employees of the organisation.
2.9 THE DIRECTORY OPERATIONAL AND ADMINISTRATIVE
INFORMATION MODEL
There are also other types of information (attributes) that need to be
stored in the Directory. Whilst user attributes are typically set and used
by users of the Directory, they are transparent to the operation of the
Directory system - telephone number is a good example of this. Their presence
or not in the DIB does not affect the actual operation of the Directory.
The system will still function perfectly well without them (although their
absence may cause considerable frustration to one or more users of the
Directory). In the '93 edition of the Standard, these types of attribute
are called user attributes. It was decided that the attributes described
in the '88 edition of the Standard most nearly match this definition, and
so all '88 defined attributes have been re-classified in the '93 Standard
as user attributes (but see w/w 2.1).
Other attributes however, are related to the operation of the Directory
itself. Some might be set by the software, in order to monitor or control
the system, e.g. the date-and-time an entry was last modified. Others might
be set by administrators or users of the Directory, and be used by the
software in order to correctly process users' requests. Access Control
attributes are examples of this type. These attributes are called Directory
operational attributes. They are part of the Directory Administrative
and Operational Information Model.
A major property of Directory operational attributes is that they are
not normally visible to ordinary users of the Directory. This means that
if a user wishes to read all the attributes in an entry (assuming they
have the required permissions - see Chapter 8), a simple Read request (§
5.6) asking for all attributes will not return any operational attributes
in the result. (Only user attributes are returned.) In order to be accessed,
operational attributes have to either be specifically named in the Read
request, or selected via a '93 extension parameter Extra Attributes.
Table 3.5 lists the Directory operational attributes that have been standardised.
Besides these 'hidden' attributes - hidden to normal users, that is
- there are also some 'hidden' entries, that are usually only visible to
administrators. These hidden entries are called subentries. Subentries
mainly hold operational and administrative information. A fuller description
of subentries is given in § 2.12.
Whether an attribute is user/collective or operational is specified
at the time that it is defined. It cannot change definitions during its
lifetime.
2.10 ATTRIBUTE HIERARCHIES
Another new concept introduced in the '93 standard is that of attribute
hierarchies. This acknowledges the fact that some attribute types may be
very similar to each other, and are in fact refinements of a more general
type. For example, telephone number is more generic than office telephone
number, which is more generic than direct dial office telephone number.
A more general attribute type is said to be a supertype of a more
specific attribute type. Conversely, a more specific attribute type is
said to be a subtype of a more generic attribute type. When accessing
the Directory for a particular attribute type, the Directory will return
any values of that type, and of any of its subtypes, that it finds. Thus
if an entry had all three types of telephone number attribute present,
and a user requested the values of the telephone number attribute, the
values of all three attribute types would be returned. If a user requested
values of the office telephone number attribute, then these values, and
those of the direct dial office telephone number would be returned. The
user is always able to tell which type of attribute is returned, e.g. which
is the direct dial number, since the actual attribute (sub)type is returned
in the answer along with the values.
2.11 DIRECTORY
ADMINISTRATIVE AUTHORITY MODEL
A significant enhancement to the '88 standard is the addition of an Administrative
Authority Model. This recognises that different parts of the DIT will be
administered, or managed, by different organisations. At some point in
the DIT, there will be a complete break between one administration and
another, whilst at other points in the DIT there will be a devolving of
some power onto sub-authorities. An example of the former might be between
the administrator of a country entry, and the administrator of an immediately
subordinate organisational entry. (A country's entry (name)
may be administered by the national PTT or the national standards body,
since these are the official representatives of the country at the ITU-T
and ISO. An organisation's entry may be administered by the organisation.)
An example of the latter might be the delegation of some authority within
an organisation to the administrator of an organisational unit. Both of
these are catered for in the administrative model, by allowing the DIT
to be divided into subtrees, that are controlled, or administered, by different
authorities. Two types of subtree are defined: autonomous administrative
areas (AAA), and inner administrative areas. Autonomous administrative
areas start at an entry in the DIT, called an autonomous administrative
point (AAP), and continue downwards until either leaves or other autonomous
administrative points are encountered (Fig. 2.5). Applying Fig. 2.5 to
the USA, the first AAP under the DIT root could be the {C=US} entry. Below
this could be entries for each of the 50 States. These might be administered
jointly by the national carriers such as AT&T and MCI, since they represent
the US at ITU-T. Below these would be entries for American organisations.
Each organisation would be completely responsible for administering their
part of the DIT, i.e. their organisation's entry and all the entries below
it (although they could always sub-contract this to a service provider).
Inner administrative areas start at an entry in the DIT - an inner administrative
point, or IAP - that is within an autonomous administrative area. (IAPs
are always subordinate to AAPs.) Inner administrative areas continue downwards
until the end of the autonomous administrative area is reached. Entries
within an inner administrative area are still under the overall control
of the autonomous administrative authority, but some degree of control
is also exercised over them by the administrator of the inner administrative
area. Inner administrative areas may be nested (Fig. 2.6), but the bottom
of all inner areas is always the bottom of the enclosing AAA (actually
the specific area, § 2.11.1). The fact that inner areas always go
to the bottom of the enclosing specific area has caused confusion at the
Standards meetings, even amongst the experts. This is because areas are
always implicitly defined - they only stop when a leaf or a new specific
administrative point (administrative entry) is reached. However, collections
of entries within an area may be explicitly defined (§ 2.12.1), and
these can always stop before the bottom of the area is reached.
2.11.1 Specific Administrative Areas
According to the Standard, administrative areas control three specific
aspects of administration. In other words, the administrative authority
for an administrative area can operate in three different roles.
-
Subschema administration is concerned with administrating the Directory
subschema that is in operation in this part of the DIT (Chapter 3 gives
a fuller description of the schema).
-
Access control administration is concerned with administrating the
security policy that is in force in this part of the DIT (Chapters 7 and
8 give a fuller description of security).
-
Collective attribute administration is concerned with administrating
the collective attributes in this part of the DIT (§ 3.11.1).
An AAA can therefore be viewed from each of these three aspects, the view
revealing either a subschema specific administrative area, an access control
specific administrative area or a collective attribute specific administrative
area. In order to visualise this, try to imagine that an AAA subtree has
been sliced horizontally into three layers, i.e. an access control specific
administrative area sandwiched between a subschema specific administrative
area and a collective attribute specific administrative area, see Fig.
2.7.
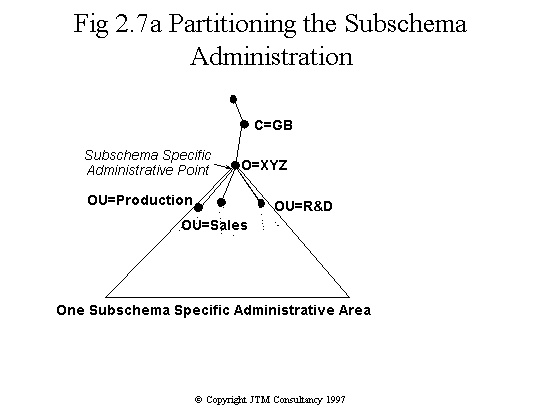
Fig. 2.7 Autonomous administrative area
Fig 2.7a Subschema administrative area
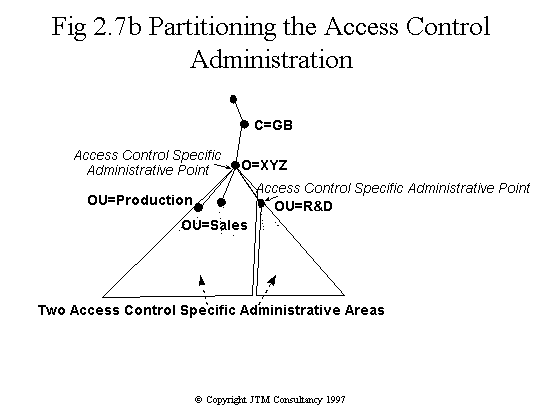
Fig 2.7b Access control administrative areas
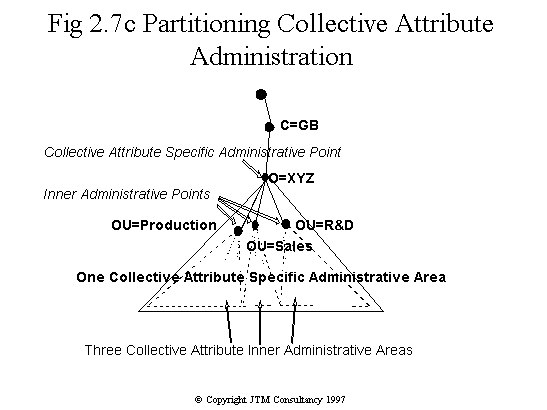
Fig 2.7c Collective attribute inner administrative
areas
For each specific aspect of administration, the AAA can be partitioned
into one or more specific administrative areas. In order to visualise this,
imagine that any one layer of the sandwich can be sliced vertically into
pieces.
In order to understand the complexity of the model, consider, for example,
the organisation {C=GB,O=XYZ} shown in Fig. 2.7. The organisation's entry
represents an autonomous administrative point, with the AAA extending down
to the leaves. The organisation consists of three operating divisions:
sales, production and R&D. The subschema needs to be consistent across
the whole organisation, so that the divisions may freely understand each
other's information. Thus the subschema specific administrative area is
congruent with the AAA. (Note that the Standard forbids subschema inner
administrative areas.) Any division which wishes to define a new data type,
must first register it at the organisational level, via the administrator
responsible for the subschema. Security policy, on the other hand, does
not need to be consistent across the whole organisation. This is because
the R&D division undertakes a lot of collaborative research with outside
institutions, and needs to impose its own (more liberal) security policy.
Thus the AAA is partitioned into two specific security administrative areas,
one covering the R&D division, and one covering the rest of the organisation.
The two administrators can thus act independently with respect to security
administration. With respect to collective attributes, it is decided that
this specific administrative area should be congruent with the AAA, so
that, for example, the main switchboard telephone number can be attributed
to every entry. However, each division is delegated authority to define
its own collective attribute inner administrative areas, to which their
own specific collective attributes may be attached as shown in the bottom
diagram of Fig. 2.7.
Operational and collective attributes can be attached to an administrative
area. They then appear to be shared by, and present in, all of the entries
enclosed within the area. It is also possible to explicitly define subsets
of the entries within an administrative area, i.e. entry collections (§
2.12.1), and to attach operational or collective attributes just to them.
Access control information, collective attributes and subschema management
make extensive use of the administrative model.
Remember that the Directory Administrative Authority Model does not
depend upon the distribution of the DIT between different systems (DSAs).
When the DIT is distributed between many DSAs, and an administrative area
spans one or more DSAs, the Directory has in-built mechanisms to ensure
that the administrative information is copied to the right systems. The
administrative information is propagated from one DSA to another via Hierarchical
Operational Bindings (§ 4.8 and § 9.19).
2.11.2 The 'Administrative Role' Directory Operational Attribute
The model defines an operational attribute, called administrative role,
that is used to identify the start of autonomous, specific and inner administrative
areas. The attribute is positioned at administrative entries, and is multi-valued.
Each value indicates one of the roles of the administrative point. Six
values are defined: one value signifies autonomous area, there is one value
for each of the specific aspects of administration, i.e. subschema, access
controls and collective attributes, and one value for each of the allowable
types of inner area (subschema cannot have an inner area). For example,
an AAP entry must hold this attribute with four values stored in it. (An
AAP is always the start of a specific area for each of the three aspects
of administration, plus it is autonomous.) A specific administrative point
below this, that identifies the start of another partition of a specific
administrative area, will contain the administrative role attribute with
a single value that identifies the specific aspect. An inner administrative
point below this will also hold the attribute, only this time its values
will be either or both of the allowed inner areas (access control and collective
attributes).
2.12 SUBENTRIES
So how and where is this operational and collective attribute information
stored in the DIT, so that it can be attached to a set of entries within
an administrative area. The original idea, as might be deduced from Fig.
2.7, was to store the shared information in the administrative points.
This information needs to comprise:
-
a description of the DIT subtree, or set of entries, to which the 'shared'
attributes apply (this is stored in a 'subtree specification' attribute);
and
-
a list of the 'shared' attributes that should be applied to a particular
DIT subtree or entry collection.
However, an entry consists of a set of unrelated attributes. Here we have
relationships between several sets of attributes. This could be solved
by creating one complex attribute, that contained both a subtree specification,
and the shared attributes. Then each value of the complex attribute would
contain the information describing one set of shared attributes. Alternatively,
and this is the method that has been chosen, the administrative entry could
be regarded as having several subentries contained within it. Each subentry
would consist of:
-
the subtree specification attribute;
-
the list of attributes that are to be applied to the subtree/collection
of entries; and
-
the RDN of the subentry (so that it can be uniquely identified).
This is shown in Fig. 2.8. But we have forgotten one thing. Each entry,
as we shall see in the Chapter 3, has an object class attribute
that controls which attributes can be stored in it. So why should not a
subentry have one too? It should, so that accounts for the final component
of a subentry as shown in Fig. 2.8.
Thus each administrative point has a set of subentries beneath it, which
are conceptually part of the administrative entry. Subentries are not visible
to normal users of the Directory. Each subentry is uniquely identified
by its own RDN. Each subentry contains a description (subtree specification)
of the DIT subtree or collection of entries that it governs. It also contains
a list of operational and collective attributes that are to be applied
to each entry within the scope of the subtree specification. Finally, this
list is controlled by an object class attribute. Subentries are used to
describe the subschema that is to control a DIT subtree, to apply collective
attributes to a set of entries, and to enforce access controls on a part
of the DIT.
2.12.1 The Subtree Specification Attribute
Subtree specifications are very comprehensive. Not only can DIT subtrees
be precisely defined, but specific types of entry within a subtree can
also be identified. The latter are sometimes known as entry collections.
Entry collections will probably not be a true subtree of the DIT, and so
the term subtree refinement is also used to describe them.
The subtree specification consists of three optional components. If
all of them are absent, then the subtree starts at the administrative point,
and contains all of the entries in the administrative area. This is the
default.
-
The first component (base) specifies the name of an entry below
the administrative point, at which the subtree is to start.
-
The second component (chop) specifies the precise shape of the DIT
chunk below the starting point (base). This might or might not be a subtree.
Chop optionally specifies where to start including entries, counting down
from the base, and where to stop including them. This is expressed as two
integers, a minimum and a maximum number of RDNs. Chop also allows particular
smaller subtrees to be excluded from the main one (using a chop before
or chop after construct). The only restriction placed on chop is that the
lowest entries must be at or above the bottom of the administrative area.
-
The third component (specification filter) selects only those entries
from within the subtree, that match the given object class (§ 3.5)
criteria. For example, to select people's entries from an organisation's
subtree, the filter would be object class = organisational person. To select
people who use X.400 Email, the filter would be object class = organisational
person and object class = MHS-User. After reading Chapter 5, you will see
that this filter is similar to the one used in the Search operation, except
that only object class criteria can be used.
Each of the components may be individually selected for inclusion in the
subtree specification. Fig. 2.9 shows the sorts of subtree (or subtree
refinements/entry collections) that can be specified by different combinations
of the above components. By way of a further example, referring to Fig.
5.3, suppose a subtree specification is to be placed in a subentry below
the {O=XYZ Plc} administrative point. The subtree refinement is to include
only the people in the R&D unit, but it is also to exclude the Communications
Team. The subtree specification would be as follows:
Base is OU=R&D,
Chop Before OU=Communications Team,
Filter on Object Class = organisational person
Once the precise shape of the subtree or collection of entries has been
defined, the administrator can then attach access controls, collective
attributes and subschema operational attributes, to the entries described
by the subtree specification.
2.13 THE DSA INFORMATION MODEL
Up to this point in time, all our deliberations have been about models
of the global Directory information, viewed as if it was held in a single
centralised database. Distribution of the data between computer systems
(DSAs) was not important. Neither was replication of the information between
systems. Once we start to look at the subset of the global information
that is held on just one system (DSA), we have left the world of the global
Directory database behind, and have entered a world where information is
only seen from a system's eye view. This system's eye view is called the
DSA Information Model. Anything that is not held within a DSA's local database
is not known about, and consequently appears not to exist. Thus the DSA
Information Model needs to consider what information an individual DSA
needs to hold in its local database, in order to successfully co-operate
with other DSAs to provide a distribution and replication transparent service
to the user. Unless the DSA holds the entire global database (this is not
too unreasonable from an organisation's initial perspective - see §
9.9), the DSA will need to know where and how its bit of the DIT fits into
the bigger picture. A typical DSA that only holds some of the DIT, will
need to have the following sorts of information:
-
the complete set of user attributes for the entries that it masters, i.e.
information about that part of the DIT that it controls. Master
means that this DSA is the holder of the master copy of the entry, and
if other copies exist elsewhere, they must have originated from here. Each
entry is only mastered in one DSA, see Chapter 6;
-
knowledge of where this set of entries fits into the global DIT, i.e. distribution
information;
-
if it holds copies of other entries, knowledge of where they came from,
and how and when they will be updated, i.e. replication (consumer) information;
and
-
if it has supplied copies of its entries to other DSAs, details about these
arrangements, i.e. replication (supplier) information.
A lot of this information is not visible in either of the Directory Information
Models. We thus need to define some additional types of entries and operational
attributes, that can hold this extra DSA information. These attributes
are described in § 2.13.1, the entries are described in § 2.13.2.
2.13.1 DSA Operational Attributes
Operational attributes that are needed by a DSA, but which are not needed
by either of the Directory Information Models, are called DSA operational
attributes. By reviewing the list in § 2.13, we can see that there
are actually two different sorts of DSA operational attribute.
DSA shared attributes are operational attributes that are dependent
on the way that the DIT is distributed and replicated between computer
systems (DSAs), but are independent of the computer systems (DSAs) in which
they are held. In other words, they always have the same value whichever
system they are stored in. The specific knowledge attribute, which contains
the names and addresses of the DSAs which hold the master and shadow copies
of a Directory entry, is an example of a DSA shared attribute. The value
of the specific knowledge attribute will be the same for a particular entry,
whichever computer system it is retrieved from.
Note. This was originally correct at the time of
its definition. It is now not strictly true, because of security or administrative
reasons, a particular administrator is allowed to remove some of the DSA
Access Point values from the attribute before copying it to another system.
In a completely open world, the shared value would be the same in all DSAs.
DSA specific attributes are operational attributes whose values
depend both on the way that the DIT is distributed and replicated between
computer systems (DSAs), and also on the specific computer systems in which
they are held. An example of a DSA specific attribute is the supplier knowledge
attribute. This is the name and address of the DSA that is providing a
copy of part of the DIT to a particular DSA. Assuming that several computer
systems are holding copies of the same entries from the DIT, and that each
system is getting the information from a different source (Chapter 6),
then the value of the supplier knowledge attribute stored in each system
will be different.
2.13.2 DSA Specific Entries
The DIT consists of Directory entries. Clearly DSAs must hold Directory
entries. A DSA will need to know the name of each entry that it holds,
as well as the entry information associated with each entry, i.e. Directory
operational and user attributes, as shown in Figs
2.1 and 2.2. However, DSAs also need to hold
other information, i.e. DSA operational attributes, along with the names
of Directory entries. Sometimes the name of an entry will be held, without
any of its associated entry information. Only DSA operational attributes
will be held with the name. DSAs need to do this, in order to link their
Directory entries to other ones in the DIT. For example, the name of a
remote entry may be held, along with a pointer saying in which DSA it actually
resides. Therefore different DSAs may hold the same DIT name, but with
different contents, the contents often being specific to the holding DSA.
When writing the Standard, it was thought to be more precise, and less
confusing, if it was said that DSAs do not hold Directory entries as such
(since their contents are fixed), but rather, that they hold DSA Specific
Entries (or DSEs). In this way different DSAs could hold the same name,
but with different contents. In other words, the contents of an entry,
as held in any given DSA, are DSA specific.
The portion of the DIT held by a particular DSA, is called the DSA Information
Tree. It is a subtree of the DIT, but it always starts at the root.
A DSA must hold all the DSEs from the root of the DIT to the Directory
entries that it holds. So for example, a DSA holding entries for the XYZ
organisation, must also hold DSEs for the root and for the country in which
XYZ is located. Fig. 2.10 shows part of a typical DSA Information Tree.
In the example, the DSA holds all the Directory entries for the XYZ organisation,
except for the entries within the credit control division. These are held
in another DSA, and are pointed to by a subordinate reference. The DSA
also holds an indirect pointer (or superior reference) to the root of the
DIT, in order to connect this DSA Information Tree into the global DIT.
(See Chapters 4 and 9 for more details.)
Figure 2.11 shows the three different views of the information held in
a particular DSE. Figure 2.12 shows the three different views of a DSA
Information Tree. The three views, Directory User, Directory Administrator
and DSA Administrator, correspond to the information that is defined in
the Directory User Information Model, the Directory Operational and Administrative
Information Model and the DSA Information Model respectively. (Real Directory
users are not restricted to one view. A normal Directory user might be
able to see administrative information and DSEs without entry information,
and an administrative user will certainly be able to see all DSEs and DSA
operational attributes. A 'real' user's view will typically depend upon
their access rights.)
Each DSA must hold, as a minimum, one or more DSA specific attributes for
each DSE that it holds. The other types of attribute are optional, as shown
in Fig. 2.10. The DSA specific attribute that must be held in each DSE,
is the DSE Type attribute. This attribute signifies the type of
a DSE, and it governs the other attributes that can be held in the DSE.
The attribute can only have one value, and this is encoded as an ASN.1
bit string. More than one bit may be set for any given DSE. Each bit has
the meaning described in Table 2.1.
So, for an entry that has been copied from another DSA, bits 3 and
11 would be set (w/w 2.3). It will be necessary to read Chapter 9 before
a full understanding of all of the meanings can be gained.
A DSA is modelled as always holding DSA specific attributes in its root
entry. One example of such an attribute, is the My Access Point attribute.
This is a DSA's own name and address. Another example is a superior reference,
which points to a DSA holding entries higher up in the DIT.
Table 2.1 The meanings of the bits in the DSE Type attribute
| BIT |
Name |
Meaning for this DSE |
| 0 |
root |
The root of the DSA Information Tree |
| 1 |
glue |
Represents knowledge of a name only. No other information
is held with it |
| 2 |
cp |
The context prefix of a naming context |
| 3 |
entry |
Holds an object entry |
| 4 |
alias |
Holds an alias entry |
| 5 |
subr |
Holds a subordinate reference |
| 6 |
nssr |
Holds a non-specific subordinate reference |
| 7 |
supr |
Holds a superior reference |
| 8 |
xr |
Holds a cross reference |
| 9 |
admPoint |
An administrative point |
| 10 |
subentry |
A subentry |
| 11 |
shadow |
Holds a shadow copy of an entry |
| 13 |
immSupr |
Holds an immediate superior reference |
| 14 |
rhob |
Holds information about a superior administrative point
or subentry, passed by a RHOB |
| 15 |
sa |
Subordinate reference DSE points to an alias entry |
WEIRD AND WONDERFUL
2.1 '88 systems make no distinction between user, collective and operational
attributes. They all have the same semantics, i.e. they only apply to the
entry in which they reside, they may be set by the user, and they are all
returned with a Read All Attributes operation (w/w 5.6). All of them except
two do not affect the operation of the Directory. They are thus most similar
to '93 user attributes. The decision was made that All Attributes defined
in the '88 standard would become user attributes in the '93 standard. Under
this '93 classification of attributes, the two '88 attributes that cause
a problem are the object class attribute and the aliased object
name attribute. (The former attribute describes the type, or class
of an entry, and this controls which attributes can be stored in it (§
3.5), and the latter is the pointer held in an alias entry, and used in
alias dereferencing.) Although they may be set and read by users, they
are clearly bound up with the operation of the Directory, and therefore
are technically operational attributes. But operational attributes were
defined as not being returned in a Read All Attributes request. It was
suggested that these two attributes should indeed be classified as operational
attributes, and that the restriction on Read All Attributes be slackened,
so that specifically named operational attributes could be returned by
this operation. However the international decision did not favour this
approach, and instead chose to classify them as user attributes, but to
add a paragraph in the Standard saying that they are really semantically
operational attributes but must remain as user attributes to facilitate
interworking with '88 systems.
2.2 The original reason for not allowing aliases to point to other aliases
was not documented. However, the author believes that it was either to
avoid looping, or to prevent aliases from having both backwards and forwards
pointers (in the original model entries used to have back pointers to their
aliases). Whichever reason it was, neither now exists in the '88 Standard.
Alias back pointers were removed at the Draft Proposal stage. Looping was
avoided by the introduction of trace information. However the restriction
on aliases was never removed, and this resulted in an extra parameter being
added to Chaining Arguments (aliased RDNs), and extra procedures being
written for Part 4 of the Standard, to enforce the restriction (§
9.13.6). After all that, the '93 edition of the Standard removed the restriction,
which caused even more procedures to be written to describe how '93 DSAs
should deal with the aliased RDNs argument!
The original model of aliases, initially proposed during the development
of the '88 Standard, had forward pointers from the alias entry to the object
entry, and back pointers from the object entry to its aliases. But the
back pointers were dropped when it was realised that modifying the relative
distinguished name of an entry, or removing an entry from the DIT, would
be too complicated to define in a distributed environment. A two-phase
commit protocol would almost certainly be needed, and many experts did
not want to introduce transaction processing into the Directory. Consequently
we can now be left with 'dangling' aliases. These are aliases that point
to a non-existent object entry, because it has been either deleted or renamed.
It is up to administrators or implementors to clean up these old aliases.
2.3 Observant readers will notice that Table 2.1 does not define bit
12. Bit 12 was originally used, during development of the '93 Standard,
to signal an entry that had been deleted from the DIT, but that had a 'name
re-use' timestamp attached to it. This indicated the time during which
the name of the entry could not be re-used to create a new entry with the
same name. The entry was thus 'dead' to users, but still 'alive' in the
DIT. It was called a Zombie DSE (the living dead!). However, the 'name
re-use' timestamp was subsequently replaced by allowing entries to have
a unique id assigned to them (§ 8.4.2). Names can then be re-used
immediately, but each re-use will involve the allocation of a different
id. This is the feature that actually appears in the '93 Standard. Whilst
the Zombie DSE is no longer needed, it still lives on in spirit, by keeping
bit 12 from being re-assigned. Who says that Standard's writers do not
have a sense of humour!

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}