The Directory Standard provides the Directory administrators with a set of rules - the Directory schema - through which they can control the information that users are allowed to store in the portions of the DIT that they administer. The application of the Directory schema to the portion of the DIT under the administrator's control, i.e. an autonomous administrative area (AAA) (or subschema specific administrative area, to be more precise), yields what is referred to as a subschema. Different subschemas will control different portions (AAAs) of the DIT. The sum total of all the subschemas will in effect be the actual schema that controls all the user information in the global Directory. (Note that the Directory schema only controls entries and user and collective attributes. Subentries and operational attributes are controlled by the Directory system schema, see § 3.12).
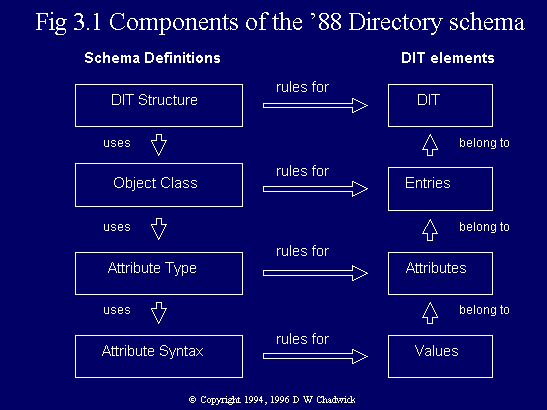
The '88 edition of the Standard provided most aspects of the schema. Fig. 3.1 shows the components of the schema as defined in the '88 edition of the Standard. The left hand column shows the components of the schema, and the right hand column shows the elements of the information that can be held in the DIT. (The latter is an alternative way of showing the elements of the information model shown in Fig. 2.1.) Fig. 3.1 shows which component of the schema controls which aspect of the information that can be stored in the Directory. Thus the component of the schema called attribute syntax controls the values that an attribute can have, whilst the schema component attribute type controls all aspects about an attribute. Fig. 3.1 also shows the relationships between the various components of the schema. The definition of a component of the schema in the left hand column of Fig. 3.1 builds upon the definition of the component immediately beneath it.
Fig. 3.1 Components of the '88 Directory schema.
The only component of the schema that was not fully
defined in the '88
Standard was the DIT structure. Some basic ground
rules were laid
in an Annex to the Standard (Annex B of Part 6), but
these were only advisory,
as they were not formally part of the Standard.
Nevertheless, the Functional
Standards groups such as the European Workshop for Open
Systems (EWOS)
and the US OSI Implementors' Workshop (OIW) made them
part of their functional
standards for the '88 Directory.
Note. Functional Standards
are standards
produced by a specific group of users of International
Standards, who define
how a set of International Standards will be used.
Options in the International
Standards are narrowed down or eliminated, restrictions
are often imposed
on the application of an International Standard,
ambiguities in the International
Standards are clarified, and omissions are filled in, by
a Functional Standard.
As work progressed after 1988, the structure rules
became more solid,
and Fig. 3.2 shows the '93 edition of the schema.
Fig. 3.2 Components of the '93 Directory schema.
In the '93 edition, the DIT structure rules have been defined, but also some new DIT content rules and name forms have been added. Notice that the '88 attribute syntax has been split into its two component parts - its ASN.1 type (syntax) and its matching rules. More about this later (§ 3.3).
Taking Fig. 3.1 as the starting point, let us work up through the layers of the schema, starting with attribute syntax.
Syntaxes are defined using the Abstract Syntax
Notation One (ASN.1)[4.1].
This language has been created, specifically for use by
OSI applications,
in order to allow, amongst other things, their data types
to be unambiguously
defined. The language defines a set of primitive types,
such as INTEGER,
BOOLEAN, and various character strings types. It also
defines the rules
for combining types together, as CHOICEs, SETs or
SEQUENCEs, so that more
complex types can be built up from simpler ones.
Note. These combinatorial rules
have their natural
English Language meanings, so that:
- CHOICE means that only one type
from a set of
ASN.1 types may be chosen when a value of the complex
type is constructed,
- SET means that each type from a
set of types
must be used when a value of the complex type is
constructed, but the order
in which the simple types occur is unimportant,
- SEQUENCE means that each type
from a set of types
must be used when a value of the complex type is
constructed, and the ordering
of the simple types must always remain the same as in the
definition.
Thus a 'Date' ASN.1 type could be built up from a SEQUENCE of three INTEGERS, the first integer being the day (with values from 1 to 31), the second integer being the month (with values from 1 to 12), and the third integer being the year (perhaps with values from 1900 to 2100). There is obviously a lot more to the ASN.1 language than this, but a tutorial on ASN.1 is outside the scope of this book. Interested readers could refer to Steedman (Steedman, 1990), or to the Standard itself [4.1]. It is sufficient for this purpose to say that an attribute syntax definition includes the ASN.1 type definition for values of the attribute. Examples of ASN.1 types are included in Figs 3.3 to 3.6.
The schema component Attribute Type is used to define (amongst other things) the syntax of the attribute's values, and the semantics of the values. For '88 edition systems, the syntax can be defined either independently as an attribute syntax definition and then imported into the attribute type definition, or it can be defined in situ as part of the attribute type definition. Independent definition means that an attribute syntax may be referenced subsequently by several different attribute type definitions. Clearly if an attribute has a very complex syntax that is extremely unlikely to be ever used by another attribute, then there is no point in separately defining the syntax. It may as well just be defined in situ in the attribute's definition. By having independent definitions for the most commonly used syntaxes, we can form a pool of Standard attribute syntaxes. These can then be used by lots of different attribute types defined in the Standard. This pool of commonly used syntaxes can also be used by Directory administrators when they define their own attribute types, peculiar to their own organisations. For example, at Salford University, there is a 'room number' attribute type, which holds a person's building and room number. This is stored in each employee's Directory entry. The syntax used for this attribute type, was 'case ignore string syntax' which is already defined in the '88 Standard, and which was already supported by the DSA software.
Formally, the '88 definition of an attribute syntax consists of specifying:
An object identifier (see Appendix A) may also be optionally assigned to an independent attribute syntax definition, in order to uniquely identify it. The assignment of an object identifier to the definition, means that it may then be referenced by several different attribute type definitions.
For example, suppose an 'integer attribute syntax' could be defined and used by both an 'Age' attribute, and a 'Number of Children' attribute. The actual definition of this attribute syntax, as it appears in the '88 Standard, is given in Fig. 3.3, and an explanation of the definition is given in § 3.3.1.
Now consider what values this syntax might have. The integer 3 would be a sensible value for both 'Age' and 'Number of Children' attributes, whereas 99 would not be a sensible value for Number of Children, and 1024 would not be a sensible value for either attribute. One might thus like to limit the range of an attribute's values, but still use a pre-defined attribute syntax. It thus is not sensible to place restrictions on values within an attribute syntax definition. Rather, when defining an attribute type using a pre-defined attribute syntax, any restrictions on the size of the attribute's values should be introduced at this stage (§ 3.4).
Matching rules are needed to answer such questions as: does 'MAC' match '_Mac_' (where _ represents a space), or does 'Mc' match 'Mac'? Does 2 come before or after 3, does 'd' come before or after 'e', is 15 less than or equal to 1111? All of these questions and more need to be answered. The DSA software needs to know how to perform all of the five types of matches defined for the Search operation, for all of the attribute values that it holds, whatever their syntax.
Thus each attribute syntax needs to have a set of
matching rules associated
with it.
Note. It is possible for the set to be
empty, i.e. for
an attribute type to have no defined matching rules.
However, if the equality
matching rule is not defined for a particular attribute
type, then the
Directory will not know how to compare for equality, a
presented value
with a value stored in the entry. In this case, a value
of the attribute
cannot be used in a distinguished name, nor can it be
modified, nor can
it be searched for.
The difference between the '93 and '88 editions of the Standard, is that in the '88 edition the two schema components were tightly coupled together in just one Attribute Syntax definition, but in the '93 edition of the standard the components were separated. The latter approach is more logical, as the following example shows. Suppose that we have two attribute types 'UNIX password' and 'Primos password' defined in our part of the DIT. Both can have the same ASN.1 syntax of Printable String. Suppose 'Grace' is a value of both attribute types (note that people always use the names of their children as passwords!). A Compare operation (§ 5.7), quoting the value 'GRACE', should return True for the Primos password, but False for the UNIX password. This is because UNIX passwords are case sensitive, and Primos passwords are not. We thus need different equality matching rules for the two passwords. Primos passwords would have a 'case insensitive' equality matching rule, whilst UNIX passwords would have a 'case sensitive' equality matching rule. In order to achieve this in the '88 edition of the Standard, the two attribute types would have to be assigned different Attribute Syntaxes, since the matching rules are integral with the syntax definition. In the '93 edition, both attributes would have the same syntax, but each attribute type definition would use different equality matching rules. (The '93 Standard therefore allows us to 'mix and match' syntaxes and matching rules in attribute type definitions.)
Formally, when attribute syntaxes and matching rules are defined, each may be allocated an object identifier (OID) for identification purposes. A '93 defined matching rule must have an OID assigned to it. An '88 attribute syntax similarly needs an OID, since it is a package of matching rules and an ASN.1 syntax. A '93 attribute syntax does not need an OID, because it is simply an ASN.1 type definition and this can be identified by its ASN.1 type reference. When a '93 attribute type is defined, separate pre-defined matching rules and an ASN.1 syntax may be imported into the attribute type definition. When an '88 attribute is defined, only a pre- defined combined attribute syntax with matching rules may be imported into the attribute type definition.
The Integer attribute syntax is intended for attributes whose values are integers.
integerSyntax ATTRIBUTE-
SYNTAX
INTEGER
MATCHES FOR EQUALITY
ORDERING
::= {attributeSyntax 9}
Two attribute values of this syntax match for equality if the integers are the same. The ordering rules for integers apply.
Within the ASN.1 macro, the first line states that
this is the (partial)
definition for the attribute syntax which is to be known
as integerSyntax.
integerSyntax is the reference - in ASN.1 this is
called a value
reference - to this definition. This value reference is
an easily understood
human alternative to the object identifier assigned to
the definition.
It is the object identifier (or its value reference) that
is imported into
the definition of attributes which use this syntax. The
second line defines
the ASN.1 type of this attribute syntax. In this case it
is INTEGER, which
is a type reference to the definition of the simple type
integer which
occurs in the ASN.1 standard [4.1]. The latter defines an
integer to be
all positive and negative integers, including zero. Thus
all attribute
values with this syntax, must be integers. The next line
of the macro states
that attributes whose syntaxes are integers, may have
equality and ordering
matches applied to them.
Note.Present matching is automatically
defined for All
Attributes, since this does not depend upon the syntax.
Approximate matching
is not defined for any attribute syntax, since the rules
for this are always
locally defined as an extension to the base
Standard.
The two sentences at the end of the definition, clarify what equality and ordering matches mean for integers. Because ordering is supported, we know that 2 comes before 3, and because equality is supported, we know that 15 decimal (presented by the user) equals the attribute value 15 (maybe stored in the computer as 1111). Substring matching is not defined for integers, so we cannot perform a match like 'all integers starting with 8'. The final line of the macro assigns an object identifier to this attribute syntax, of 2 5 5 9. (In another part of the standard, Annex B of Part 2 (1988), attributeSyntax is given the object identifier (OID) 2 5 5 - see Appendix A.)
There should be no difference in the semantics of the '93 and '88 definitions (w/w 3.6). You will note however, that the notation of the definition has changed somewhat (w/w 3.4). The ASN.1 Macro notation [4.1] has been replaced by a newer ASN.1 Information Object notation [4.2]. In this notation, each matching rule has been assigned:
integerMatch MATCHING-RULE
::= {
SYNTAX &nb
sp;
INTEGER
ID &
nbsp; &nbs
p;
{id-mr-integerMatch} }
The rule returns TRUE if the integers are the same.
6.2.3 Integer Ordering Match
The Integer Ordering Match rule compares a presented value with an attribute value of type INTEGER
integerOrderingMatch MATCHING-
RULE
::= {
SYNTAX &nb
sp;
INTEGER
ID &
nbsp; &nbs
p; &
nbsp;
{id-mr-integerOrderingMatch} }
The rule returns TRUE if the value of the attribute is less than the presented value.
The Case Ignore String attribute syntax is intended for attributes whose values are strings (either T.61 Strings or Printable Strings), but where the case (upper or lower) is not significant for comparison purposes (e.g. "Dundee" and "DUNDEE" match)
caseIgnoreStringSyntax ATTRIBUTE-
SYNTAX
CHOICE (T61String,
PrintableString)
MATCHES FOR EQUALITY
SUBSTRINGS
::= (attributeSyntax 4)
The rules for matching are identical to those for the Case Exact String attribute syntax, except that characters that differ only in their case are considered identical.
From line 1 of the macro, one can see that the value
reference for this
is caseIgnoreStringSyntax, and that the attribute
syntax is a choice
between PrintableString and T61String.
Note. T61String is the string defined
by CCITT for use
in teletex transmissions.
Case ignore strings can be matched for equality and
substrings, but
ordering is not defined. Thus, because ordering is not
defined, we will
never know if 'd' comes before or after 'e'! It is
therefore not possible
to search for people whose names are greater than or
equal to 'd' (assuming
of course, that people's names are defined to have the
case ignore string
syntax, which it just so happens they have, see §
3.4). We can however
search for names that start with 'Mac', or end with
'son', or contain 'mit',
because substring matching is defined. The text
accompanying the macro
tells us that the case of the characters is not
important, thus we will
get a match with names that start with 'MAC', or end with
'SoN' or contain
'mIT'. Additional text in the Standard tells us that
leading and trailing
spaces should be ignored, and that multiple spaces equate
to a single space.
Thus '_D___Chadwick_' matches 'D_Chadwick' (where _
represents a space).
There is also a description of how T61 and Printable
strings can be compared
for equality. The final line of the macro assigns the
object identifier
2 5 5 4 to caseIgnoreStringSyntax.
5 &nbs p; Many of the attributes defined in this Specification are based on a common ASN.1 syntax:
Some implementations (i.e. 88 editions - ed) of the Directory do not support the last of these choices, and will not be able to generate, match, or display attributes having such a syntax.
6.1.1 Case Ignore Match
The Case Ignore Match rule compares for equality a presented string with an attribute value of type DirectoryString, without regard to the case (upper or lower) of the strings (e.g. "Dundee" and "DUNDEE" match).
caseIgnoreMatch MATCHING-RULE ::= {
SYNTAX DirectoryString {ub-
match}
ID {id-mr-caseIgnoreMatch}
}
The rule returns TRUE if the strings are the same length and corresponding characters are identical except possibly with regard to case.
Where the strings being matched are of different ASN.1 syntax, the comparison proceeds as normal so long as the corresponding characters are in both character sets. Otherwise matching fails.
6.1.2 Case Ignore Ordering Match
The Case Ignore Ordering March rule compares the collation order of a presented string with an attribute value of type DirectoryString, without regard to the case (upper or lower) of the strings.
caseIgnoreOrderingMatch MATCHING-RULE ::= {
SYNTAX DirectoryString {ub-
match}
ID {id-mr-
caseIgnoreOrderingMatch} }
The rule returns TRUE if the attribute value is "less" or appears earlier than the presented value, when the strings are compared using the normal collation order for their syntax after lower-case letters in both strings have been replaced by their upper-case equivalents.
Where the strings being matched are of different ASN.1 syntax, the comparison proceeds as normal so long as the corresponding characters are in both character sets. Otherwise matching fails.
6.1.3 Case Ignore Substrings Match
The Case Ignore Substrings Match rule determines whether a presented value is a substring of an attribute value of type DirectoryString, without regard to the case (upper or lower) of the strings.
caseIgnoreSubstringsMatch MATCHING-RULE ::= {
SYNTAX SubstringAssertion
ID {id-mr-
caseIgnoreSubstringsMatch} }
SubstringAssertion ::= SEQUENCE
OF CHOICE {
initial [0] DirectoryString {ub-
match},
any [1] DirectoryString {ub-
match},
final [2] DirectoryString {ub-
match} }
- at most one initial and
one final
component
The rule returns TRUE if there is a partitioning of the attribute value (into portions) such that:
- the specified substrings (initial, any, final) match different portions of the value in the order of the strings sequence;
- initial, if present, matches the first portion of the value;
- final, if present, matches the last portion of the value;
- any, if present, matches some arbitrary portion of the value.
There shall be at most one initial, and at most one final in strings. If initial is present, it shall be the first element of strings. If final is present, it shall be the last element of strings. There shall be zero or more any in strings.
For a component of substrings to match a portion of the attribute value, corresponding characters must be identical, except in regard to case. Where the strings being matched are of different ASN.1 syntax, the comparison proceeds as normal so long as the corresponding characters are in both character sets. Otherwise matching fails.
This time there are some differences in the definitions. First of all, the wording has been significantly lengthened, in order to remove ambiguities. Secondly, the following changes have been made.
By now you should have grasped the main ideas behind matching rules. To summarise, a matching rule definition describes:
The '93 Standard also specifies a 'keyword equality' matching rule. The user presents a keyword value, and the system will search through the values of an attribute that supports this matching rule. If a stored value contains the keyword, it is selected. (It is implementation specific how keywords are identified in attribute values.)
Matching rules can be locally defined that will match attribute values that are approximately the same as presented values. Though no approximate matching rules have been internationally standardised, local ones have been used to good effect in several implementations. The Soundex algorithm (Knuth, 1973) works by stripping out vowels, and mapping the remaining consonants into a subset that each have distinctive sounds. Presented and stored values are then compared in this reduced name space. It enables users to locate entries, even though they may have misspelt or incorrectly guessed the name of an entry in the DIT.
Table 3.1 A selection of standardised attribute syntaxes and matching rules
|
|
|
|
| Object Identifier Syntax | OBJECT IDENTIFIER | Object Identifier (Equality) Match |
| Case Ignore String Syntax | Directory String | Case Ignore (Equality) Match
Case Ignore Ordering Match Case Ignore Substrings Match |
| Case Exact String Syntax | Directory String | Case Exact (Equality) Match
Case Exact Ordering Match Case Exact Substrings Match |
| Distinguished Name Syntax | Distinguished Name | Distinguished Name (Equality) Match |
| UTC Time Syntax | UTC Time | UTC Time (Equality) Match
UTC Time Ordering Match |
| Boolean Syntax | BOOLEAN | Boolean (Equality) Match |
| Telephone Number Syntax | Printable String | Telephone Number (Equality) Match
Telephone Number Substrings Match |
{kind=link}
{kind=link}