Knowledge of an attribute's syntax will stop ludicrous values being added to an attribute. For example, it would not be sensible to be able to add the value 'MacPherson' to an attribute of type 'Age'. However, MacPherson may be a very sensible value for an attribute of type 'Front suspension'. Through knowledge of an attribute's ASN.1 syntax (in this case 'Age' would be defined to be of type integer, and 'Front suspension' of type Directory String), an implementation will be able to control this sort of ludicrous addition to the Directory database.
One further control that can be placed over values of an attribute, is the range, or size of the value. Thus it is possible to limit an 'Age' attribute to lie in the range 1 to 120, and 'Number of Children' to the range 0 to 10. A string attribute could be limited to 20 characters. Restricting the size of an attribute's value(s) is done at the time that the attribute type is defined (w/w 3.1). Through knowledge of the size restrictions applying to an attribute, an implementation can stop outrageous values being added to an attribute. Thus a value of 99 could be added to an 'Age' attribute, but not to a 'Number of Children' attribute.
Attribute type definitions also contain a description of the semantics of the attribute. Many attributes may share the same syntax, but apply different meanings to the values. For example, the attribute types 'common name' and 'description' share the same syntax ('Case Ignore String' syntax in the '88 Standard, and 'Directory String' in the '93 Standard), but have different semantics applied to them. Whereas 'The Information Technology Institute (ITI) was set up jointly by Government and Industry to teach information technology to undergraduates' could be a good description of the ITI's entry in the DIT, it would not be a good common name for the entry. Controlling the addition of values to an attribute, that meet the defined semantics, is therefore much more problematical, and hard to incorporate into an implementation. This must usually be left up to the user of the Directory. The implementation would only be able to control the length of a string, and not its meaning.
Besides knowing the type of the attribute, one needs to know whether single or multiple values can be added. An attribute of type 'Age' should be single valued (except perhaps for people born on February 29), whereas 'telephone number' could quite sensibly be multi-valued. When defining an attribute's type, it is also necessary to state whether it can be multiply valued or not. Perhaps surprisingly, the default is multi-valued, so that single valued attributes are the exception.
Additional components are needed in the '93 definition of an attribute type. We have already covered the fact that the matching rules need to be individually specified for each attribute type, whereas in the '88 Standard this was implicit in the attribute syntax definition. Also, since the information model is much richer in the '93 Standard, attributes now have to be classified more precisely. The '88 Standard did not differentiate between types of attribute. The '93 Standard does. So the '93 definition must now say whether the attribute is a user, user collective, Directory operational, DSA shared operational, or DSA specific operational attribute. The default is 'user', since this was the only type of attribute defined in the '88 Standard. If the attribute is an operational attribute, it is also necessary to state whether the DSA software, or the (administrative) user, keeps the attribute value(s) up to date. For example, the modify timestamp attribute is only updated by the software, but the EntryACI (access control) attribute is updated by the (administrative) user. The default is for the user to update the attribute. Finally, the '93 Standard has introduced the concept of attribute hierarchies. If an attribute is a sub-type of an already defined attribute type, its definition should make this clear (Fig. 3.8). Hence '93 attribute type definitions are often more complex than '88 ones, but due to the clever use of the defaults, '93 user attribute definitions are very similar to '88 definitions.
Finally, every attribute type has to have a good old object identifier associated with it. This is essential for attributes - both '88 and '93 ones - since the protocol messages passed between components of the Directory system use an attribute's object identifier to identify the accompanying attribute values. Attribute object identifiers are also used in the Directory system schema, for controlling the types of attribute that may be added in an AAA (§ 3.13). Each attribute type defined in the Standard is allocated an object identifier. When organisations define their own attribute types, they need the ability to attach an object identifier to it. Appendix A briefly describes how organisations can obtain their own object identifiers.
The Country Name attribute type specifies a country. When used as a component of a directory name, it identifies the country in which the named object is physically located or with which it is associated in some other important way.
An attribute value for country name is a string chosen from ISO 3166.
countryName ATTRIBUTE
WITH ATTRIBUTE-SYNTAX
PrintableString (SIZE (2)) -- IS 3166 codes only
MATCHES FOR EQUALITY
SINGLE VALUE
::= (attributeType 6)
The matching rule for values of this type is the same as that for caseIgnoreStringSyntax.
The opening paragraph defines the semantics of this attribute type.
From line one of the ASN.1 ATTRIBUTE Macro, one can see that the value
reference for the attribute type is countryName. This reference
will subsequently be used in an object class definition (§ 3.5). From
lines two and three one can see that the attribute's syntax is a PrintableString,
of size two characters, with the two characters being the ones defined
in the standard ISO 3166 [7.2]. This standard assigns two character mnemonics
to all countries in the world, for example, the United Kingdom is assigned
the characters 'GB', and the United States of America the characters 'US'.
Because PrintableString is not a pre-defined attribute syntax - it is an
ASN.1 type - no matching rules exist for it. Therefore the matching rules
have to be included in the attribute type definition (i.e. the attribute
syntax is defined in situ). Only equality matching is defined for
country names, and this is stated to be the same as for case ignore strings
(it thus is not possible to match on countries, say beginning with the
letter 'G', which requires substring matching to be supported).
Note. Implementations may always support extra matching
rules such as substring match, and approximate match e.g. so that UK matches
GB.
Line five of the macro states that the attribute can only be single valued, whilst line six assigns the object identifier 2 5 4 6 to the countryName attribute type (attributeType is assigned the object identifier 2 5 4 in Annex B of Part 2 of the Standard).
The Name attribute type is the attribute supertype from which string attribute types typically used for naming may be formed.
name ATTRIBUTE ::= {
WITH SYNTAX
DirectoryString {MAX}
EQUALITY MATCHING RULE
caseIgnoreMatch
SUBSTRINGS MATCHING RULE
caseIgnoreSubstringsMatch
ID
{id-at-name} }
5.3.1 Country Name
The Country Name attribute type specifies a country. When used as a component of a directory name, it identifies the country in which the named object is physically located or with which it is associated in some other important way.
An attribute value for country name is a string chosen from ISO 3166.
countryName ATTRIBUTE ::= {
SUBTYPE OF
name
WITH SYNTAX PrintableString
(SIZE (2)) - IS 3166 codes only
SINGLE VALUE TRUE
ID
{id-at-countryName} }
By way of contrast, Fig. 3.8 shows the '93 definition of the same attribute. This time the definition uses the ASN.1 Information Object Class notation, instead of the ASN.1 Macro notation.
As country name is now a subtype of the generic name attribute, that definition is also included in Fig 3.8. In fact, the '88 and '93 definitions are almost identical (even though the syntax of the definitions is considerably different, see w/w 3.4). The only changes are those due to the inheritance of the extra matching rule (SUBSTRINGS) which has come from the 'name' super-attribute type. This means that, for example, a '93 system will be able to match on country starts with 'c', which an '88 system could not do. One other small difference is that 'id-at-xxx' has replaced the value reference to the object identifier attributeType n. This is a useful substitution, as confusion was sometimes caused by the '88 Standard using the same term (attributeType) for two different concepts. The actual value for the object identifier, 2 5 4 6, has remained the same. The '93 definition tells us that the country name attribute is not a collective attribute, nor an operational attribute, since the default is user attribute.
The Common Name attribute type specifies an identifier of an object. A Common Name is not a directory name; it is a (possibly ambiguous) name by which the object is commonly known in some limited scope (such as an organisation) and conforms to the naming conventions of the country or culture with which it is associated.
An attribute value for common name is a string chosen either by the person or organisation it describes or the organisation responsible for the object it describes for devices and application entities. For example, a typical name of a person in an English speaking country comprises a personal title (e.g. Mr, Ms, Dr, Professor, Sir, Lord), a first name, middle name(s), last name, generational qualifier (if any, e.g. Jr.) and decorations and awards (if any, e.g. QC).
Examples
CN = "Mr Robin Lachlan McLeod BSc(Hons) CEng MIEE"
CN = "Divisional Coordination Committee"
CN = "High Speed Modem"
Any variants should be associated with the named object as separate and alternative attribute values.
Other common variants should also be admitted e.g. use of a middle name as a preferred first name; use of "Bill" in place of "William", etc.
commonName ATTRIBUTE
WITH ATTRIBUTE-SYNTAX
caseIgnoreStringSyntax
(SIZE(1..ub-common-name))
::= {attributeType 3}
As a final example, Fig. 3.9 shows the definition of common name as it appears in the '88 Standard. The opening paragraph describes the semantics of this attribute type, whilst the second paragraph tries to constrain values that may be given to the string. One can see how difficult this is in an international standard! After the examples, the reader is told that alternative variants of the name should be added to the attribute as other values. So the values of the common name attribute in a Directory entry might be :
David Chadwick
Dr D W Chadwick
Dave Chadwick
Dr David Chadwick
etc.
One of these would be chosen as the distinguished value, to form the RDN. The other values would be useful for people searching through the Directory to find it.
On examining the ASN.1 macro, one can see that the value reference for
this attribute is commonName (line 1), that the attribute has the
case ignore string syntax (line 3), that the string size should be between
1 and ub-common-name (defined in Annex C of Part 6 to be 64) characters
(w/w 3.1) and that the object identifier assigned to this attribute is
2 5 4 3. The attribute can be multi-valued, because the SINGLE VALUE constraint
is not imposed.
Note. The Attribute Type Macro Definition states
that instances of the macro should include SINGLE VALUE, MULTI VALUE or
nothing. If nothing is present, MULTI VALUE is taken to be the default.
The Common Name attribute type specifies an identifier of an object. A Common Name is not a directory name; it is a (possibly ambiguous) name by which the object is commonly known in some limited scope (such as an organisation) and conforms to the naming conventions of the country or culture with which it is associated.
An attribute value for common name is a string chosen either by the person or organisation it describes or the organisation responsible for the object it describes for devices and application entities. For example, a typical name of a person in an English speaking country comprises a personal title (e.g. Mr, Ms, Dr, Professor, Sir, Lord), a first name, middle name(s), last name, generational qualifier (if any, e.g. Jr.) and decorations and awards (if any, e.g. QC).
Examples
CN = "Mr Robin Lachlan McLeod BSc(Hons) CEng MIEE"
CN = "Divisional Coordination Committee"
CN = "High Speed Modem"
Any variants should be associated with the named object as separate and alternative attribute values.
Other common variants should also be admitted e.g. use of a middle name as a preferred first name; use of "Bill" in place of "William", etc.
commonName ATTRIBUTE ::= {
SUBTYPE OF name
WITH SYNTAX DirectoryString {ub-common-name}
ID {id-at-commonName} }
| Attribute Type |
|
|
| Aliased Object Name |
|
Points to the entry that this is an alias of |
| Description |
|
Describes the object whose entry this is |
| Facsimile Telephone Number |
|
The fax number on which you can contact the object (person) described by this entry |
| Role Occupant |
|
The distinguished name of the person who occupies this role |
| Search Guide |
|
Contains suggested criteria for building Search filters, to be used for searching the subtree below this node |
| Member |
|
Lists the names of the entries that make up this group |
| Owner |
|
The name of the 'owner' of this entry |
| Object Class |
|
The class of object this entry is |
| Post Office Box |
|
The PO Box number through which you can contact the object (person) described by this entry |
| Presentation Address |
|
The presentation address of the OSI application entity described by this entry |
| User Certificate |
|
The certified public key of this Directory object |
So, the formal definition of an object class involves specifying:
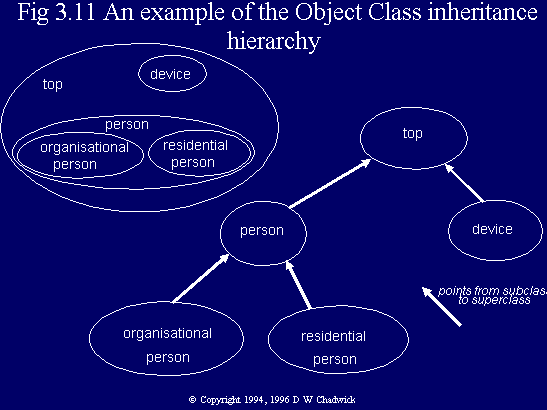
Fig. 3.11 An example of the object class inheritance hierarchy.
The Standard has defined one object class that is the most generic of all, and this is called top. All other object classes are subclasses of top. (This restriction has been slightly relaxed in the '93 Standard, see § 3.5.3 and w/w 3.2.) Whatever attributes are defined for top, will be inherited by all other Directory object classes. Figure 3.11 shows part of the object class hierarchy defined in the Standard, with a particular emphasis on 'person' objects. The accompanying Venn diagram, shows that 'person' objects are a subset of top objects (these are really the set of all Directory objects), and that organisational person's are a subset of person's.
'88 Macro notation
top OBJECT-CLASS
MUST CONTAIN {objectClass}
::= {objectClass 0}
(Taken from 9.4.2 and 9.4.8.1 of Part 2, and 6.1 of Part 7 of the '88 Standard)
top is an abstract object class used as a superclass of all structural object classes.
'93 Information Object Class notation
top OBJECT-CLASS ::= {
KIND
abstract
MUST CONTAIN {objectClass}
ID
id-oc-top }
(Taken from 8.3.1 and 12.3.3 of Part 2 of the (draft) '93 Standard.)
As an example, Fig. 3.12 shows the definition of the object class top,
as it appears in the Standard. Note again the use of the ASN.1 Macro notation
('88 Standard) or Information Object Class notation ('93 Standard) as a
compact way of recording part of the definition.
Note. ASN.1 Information Object Classes are
not related to Directory Object Classes. It is unfortunate that the term
object class is so widely used.
The textual part of the definition records that all other object classes
must be a subclass of top (in the '93 Standard this is relaxed to all structural
object classes). The value reference for the definition is top. Line two
of the Macro, line 3 of the Information Object, states that all objects
of class top (and therefore all its subclasses) must contain the objectClass
attribute (§ 3.5.4). Line 2 of the Information Object says that top
is an abstract object class. The last line assigns top an object identifier
of 2 5 6 0 (Annex B of Part 2 assigns an object identifier of 2 5 6 to
objectClass.) Note that the value references to objectClass in lines 2
and 3 of the Macro are actually to two different object identifiers, but
the context makes it clear that the first one is to an attribute called
objectClass, and the second one is to the object identifier stub that is
the common precursor to all object class object identifiers. This confusion
has been removed in the '93 Standard by the definition of an alternate
value reference, id-oc-top, for the object identifier of 'top'. (The OID
still remains the same.)
Top has just one mandatory attribute type defined for it, and this is the objectClass attribute. (The objectClass attribute says what type of object a particular entry describes.) Since all (structural) object classes are subclasses of top, all (structural) object classes inherit the mandatory attribute objectClass. Thus all entries in the Directory must have an objectClass attribute (as well as any other attributes that are defined for their particular object class).
...the value of top need not be present so long as some other value is present.
The '88 ASN.1 Macro Notation definition
objectClass ATTRIBUTE
WITH ATTRIBUTE-SYNTAX objectIdentifierSyntax
::= {attributeType 0}
(Taken from 7.4.4, 9.4.3 and 9.5.4 of Part 2, and 5.1.1 of Part 6 of the '88 Standard)
The '93 ASN.1 Information Object Class Notation definition
objectClass ATTRIBUTE {
WITH SYNTAX OBJECT IDENTIFIER
EQUALITY MATCHING RULE objectIdentifierMatch
ID {id-at-objectClass} }
(Taken from 12.4.6 of Part 2 of the (draft) '93 Standard)
An organisational person is a subclass of a person object class. No more mandatory attributes are necessary for these entries, although 18 further optional attributes may be added to them.
The Person object class is used to define entries representing
people generically.
| '88 Macro notation
person OBJECT-CLASS
|
'93 Information Object notation
person OBJECT-CLASS ::= {
|
6.8 Organizational Person 6.6 Organizational Person
The Organizational Person object class is used to define entries representing people employed by, or in some other important way associated with, an organisation.
| '88 Macro notation
organizationalPerson OBJECT - CLASS
|
'93 Information Object notation
organizationalPerson OBJECT-CLASS ::= {
|
Note that the use of attribute sets is purely a notation convenience, so that common sets of attributes may be grouped together. Then the same set of attribute types can be easily introduced into several different object class definitions by a single line of text, rather than having to repeat the whole set each time. Attribute sets are not visible in the Directory service or protocol.
Finally, the object identifier 2 5 6 7 is assigned to the organisational person object class.
Note that none of the object classes are allowed to contain collective attributes in their lists of mandatory and optional attribute types. Only normal user attributes can be placed there. Collective attributes are sanctioned for an entry via the DIT content rule for the entry (§ 3.8.1).
Table 3.3 The object classes defined in the Standard
Selected Object Classes
| Standard Object Class | Used to Characterise |
| Top | All DIT entries |
| Alias | Alias entries |
| Country | Country entries |
| Locality | Locality entries such as: State, Region, County or Department |
| Organization | Organisation entries |
| Organizational Unit | Organisational unit entries such as: Division, Unit or Department |
| Person | Generic properties of people's entries |
| Organizational Person | Entries for people within their organisation |
| Organizational Role | Role entries such as: Chairman, Managing Director, or Vice President |
| Group of Names | Entries which hold a list of names such as: mailing lists, team membership, or committee members |
| Residential Person | Entries for residential people |
| Application Process | Entries for application processes |
| Application Entity | Entries for application entities |
| DSA | Entries for DSAs |
| Device | Entries for physical devices such as: modems and line printers |
| Strong Authentication User | Entries which can strongly authenticate each other such as: DSAs and organisational people |
| Certification Authority | Entries for certification authorities |
{kind=link}