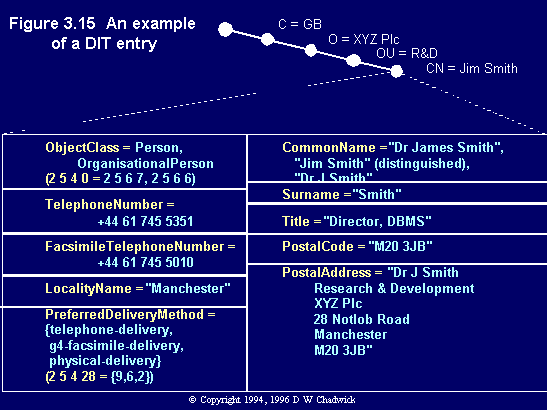
Fig. 3.15 An example of a DIT entry.
Each attribute type is logically stored in an entry as its object identifier, rather than as a mnemonic. It is up to the human interface to convert these into human readable strings when the attributes are retrieved. (However, Fig. 3.15 only shows the object identifiers for two attribute types, ObjectClass and PreferredDeliveryMethod.)
Jim Smith does not use electronic mail. So there are no X.400 attributes in his entry. He prefers to use the telephone, or fax, or paper mail. There is a preferred delivery method attribute which informs people of his preferences for communications. This directs people initially to use his telephone number (which is also stored in his entry), then subsequently to use his fax number, and finally to use his postal address. The preferred delivery method attribute syntax is actually a sequence of integers. So what is stored in the entry is the sequence of integers which represents the delivery methods, in order of preference. The Standard actually defines ten different delivery methods, and allocates the numbers 0 to 9 to them. Only three values are actually shown, those of telephone, group 4 fax and postal delivery. These values are shown in braces {}.
Note that the entry contains the three mandatory attribute types (object class from top, common name and surname from person) and seven of the optional types allowed for an organisational person. No other attribute types are present.
But what if the administrator wanted to add some other, possibly non-standardised, attribute types to the entry? I already mentioned in § 3.2 that at Salford we had created a room number attribute type. There are a number of possible solutions to this. One mechanism is to define a subclass of the existing object class, and to add the additional attribute(s) to the MUST or MAY CONTAIN list. Another way is to create an auxiliary object class containing the list of attributes and to invoke either multiple inheritance or multiple object class membership (see below), and a final way is by creating either an '88 unregistered object class (§ 3.8) or a '92 DIT content rule (§ 3.8.1).
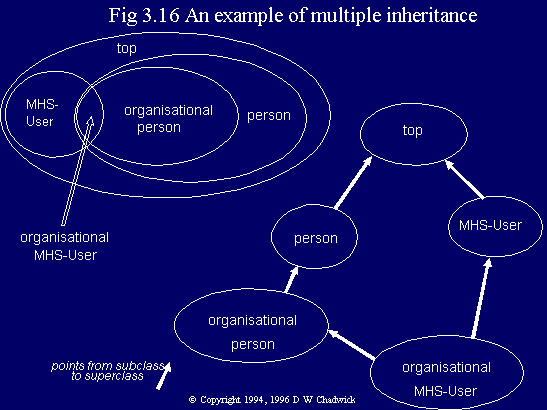
Multiple inheritance allows a new object class to be created not just as a subclass of one superclass, but as a subclass of several superclasses. In this way the new object class inherits the properties (i.e. mandatory and optional attributes) of all of its parent superclasses. At the same time, further mandatory and optional attributes can be incorporated into the definition of this new object class. Fig. 3.16 gives an example of multiple inheritance. A new object class 'organisational MHS-User is defined, which inherits its attributes from both MHS-User and organisational person. Similarly, residential MHS-User could be created from MHS-User and residential person object classes; and EDI-MHS-User from MHS-User and EDI-User object classes etc.
Fig. 3.16 An example of multiple inheritance.
Whilst this mechanism is documented and explicitly described in the '93 edition of the Standard, there was insufficient time to explicitly add the feature to the '88 edition of the Standard. It was covertly, though incompletely, added by some textual ambiguities in the '88 Standard (see Fig. 3.11 which mentions superclass(es) to which the entry belongs). The '93 edition of the Standard incorporates multiple inheritance in the following way. Taking Fig. 3.16, the organisational MHS-User object class could be defined as a new structural object class, with two super-classes. It could have additional MUST and MAY CONTAIN attributes defined for it (although none have been assigned in this example). It would need to be assigned an object identifier, xxx. The definition would be as follows:
organisationalMHS-User OBJECT-CLASS ::= {
SUBCLASS OF {organisationalPerson|MHS-User}
ID {xxx} }
The object class attribute of one of these entries in the DIT will then contain four values: person, organisational person, MHS-User, and organisational MHS-User.
However, multiple inheritance as described above still does not reduce the number of new object classes that needs to be defined. Another way is needed.
A similar effect to multiple inheritance is achieved by allowing an entry to belong to multiple object classes. In this case, a new object class does not need to be defined. Instead the object class attribute contains a series of unrelated superclass chains. The entry is a member of each of the object classes at the bottom of each of these chains. Its allowed attributes are the union of those allowed for each of the object classes that it is a member of. Taking the example of the MHS-User organisation person described above, an entry would be a member of both the organisational person object class and the MHS-User object class. Its object class attribute would contain three values: person, organisational person and MHS-User. An entry of this multiple class would be able to hold exactly the same set of attributes as the organisational MHS-User object class formed through the multiple inheritance example above. The major difference then, between multiple inheritance and being a member of multiple object classes, is that for the former, a new object class is defined. (Also further mandatory and optional attributes can be added to the new object class definition, whilst this facility does not appear to be available through the multiple object class route. But wait for DIT content rules described in § 3.8.1.)
Multiple object class membership is explicitly excluded by the '88 standard, since each entry must be a member of precisely one object class. However, the scheme crept in almost un-noticed, via the back door, through unregistered object classes (§ 3.8). On the other hand, the '93 standard explicitly allows multiple object class membership.
The two schemes can be used as follows. If several auxiliary object classes are defined, each of which contain a small set of related attributes, then many different classes of object can be created by either subclassing from different combinations of these classes (multiple inheritance), or by creating entries which are members of different combinations of these classes (multiple class membership). If the auxiliary classes are widely known, this will aid interworking, and minimise configuration management.
We thus have an entry whose actual object class cannot be determined from reading the values of its object class attribute. Only its superclasses can be determined. Someone who reads all the attributes from an entry that is, in fact, a member of an unregistered object class, will find all the attributes that are expected from the object class attribute of the entry. In addition, the user will find other attributes that were not expected. (This is the solution we adopted at Salford for the room number attribute.)
Unregistered object classes were specifically allowed by the '88 edition of the Standard, so that unnecessary object classes did not need to be defined/registered. Unregistered object classes allow entries to contain additional attributes to those expected from its object class attribute, without needing to record this in the Directory subschema. At the limit, the use of unregistered object classes can be taken as a licence by an implementation/administrator not to police at all the optional attributes associated with an object class definition. An entry of an unregistered object class is permitted to possess any attribute (over and above the minimum defined as mandatory for the object class of the entry), provided only that the attribute is known about by the implementation. Realistically, unregistered object classes allow administrators to select internationally defined object classes for the entries that are to be stored in the portion of the DIT under their control, and to allow them to be refined in an organisationally specific way with purposely defined additional attributes. This allows the administrator to change the contents of entries, as and when new requirements are defined, without changing the entry's object class.
The alternative '88 solution requires the definition of an organisational specific object class, which is either a subclass of a structural object class, or an auxiliary object class. This new object class will include the new purposely defined extra attributes. However, as the needs of the organisation evolve, new subclasses or auxiliary classes will need to be defined, in order to incorporate the new/changed attribute type requirements. Unregistered object classes negate this need.
Another consequence of unregistered object classes, is that if the unregistered class was created from a number of superclasses (multiple inheritance), then the entry would appear to be a member of multiple object classes, since the unregistered class would not appear in the object class attribute of the entry. This is how multiple object class membership could occur in '88 implementations.
The '93 edition of the Standard has replaced the concept of unregistered object classes, with the new subschema component DIT content rules. These document the variances of entries from their registered object classes, as well as listing the multiple object classes that an entry is a member of.
A DIT content rule specifies the following for entries of a particular structural object class:
Using Fig. 3.16 as an example, an entry of structural object class organisational person could be allowed to hold all the attributes of an organisational MHS-User object, by defining a DIT content rule for it, of:
'organisational person' DIT content rule is used for
entries of structural object class 'organisational
person'.
They may be also of the auxiliary object class 'MHS-User'.
In the Standard, this natural English definition is replaced by an ASN.1 Information Object Class as shown below:
organisationalPerson CONTENT-RULE ::= {
STRUCTURAL OBJECT CLASS organisationalPerson
AUXILIARY OBJECT CLASS MHS-User }
Notice that we have not actually defined a new object class organisational MHS-User. Instead, an entry covered by this rule may be a member of up to two object classes. It is always a member of its structural object class, and in addition, it may also be a member of any of the auxiliary object classes (just one in this example). So in this case, the object class attribute of an entry governed by this DIT content rule may contain three values: person, organisational person and MHS-User. The other attributes of the entry would be exactly the same as in § 3.7.
An entry belongs to just one structural object class. This governs its position in the DIT, the way it is named, and some of its mandatory and optional attributes. The entry can belong to further auxiliary object classes, but these only control further mandatory and optional attributes that the entry can have. Object classes are identified as structural or auxiliary when they are first defined. So organisational person is defined as a structural object class, and MHS-User as an auxiliary object class.
Finally, it is worth re-emphasising that an entry may only contain a collective attribute, if it is specified in its DIT content rule (§ 3.11.1).
In the '88 Standard both of these subschema components are described as a DIT structure rule. An informative annex - Annex B of Part 7 - gives examples of possible DIT structures and name forms, but they are not actually part of the '88 Standard. (This did not stop the functional standards groups seizing upon them and making them part of their functional standards [3.5]. '88 implementations which are conformant to the functional standards will have to support these structures as a minimum.) The '93 Standard has taken a more formal approach, by providing a formal notation for defining instances of both of these subschema components. Also a set of useful name forms has been defined in the Standard. It is hoped that these will be generally used by Directory administrators.
Formally, the specification of a name form consists of:
Name forms can only be specified for structural object classes. Abstract and auxiliary object classes cannot, on their own, completely define the contents of named entries in the DIT. They only add supplemental information to entries of structural object classes. Hence name forms cannot be specified for these object classes.
Every entry in the DIT must have a name form controlling it, otherwise it cannot be added to the DIT. Fig. 3.17 shows an example of a name form, as it is specified in the ASN.1 Information Object notation, in structured English, and in the text from Annex B of Part 7 of the '88 Standard. For example, the Standard recommends that country entries are named with the country name attribute type. Name forms in ASN.1 are nothing more than a formal way of writing what was written in perfectly good English in Annex B of Part 7 of the '88 Standard! So the inexperienced might think that we have taken a great leap backwards in ease of understanding, and a great leap forward in gobble-de-gook!
7.1 Country name form
The Country name form specifies how entries of object class country may be named.
countryNameForm
NAME-FORM ::= {
NAMES
country
WITH ATTRIBUTES {countryName}
ID
{id-nf-countryNameForm}}
Structured English
Country Name Form is used in
naming entries of structural object class 'country'.
The attribute used for the RDN must be 'country name'.
The object identifier for this definition is 2 5 15 0 (id-nf-countryNameForm).
'88 Standard Informative Annex from Part 7
B.1 Country
Attribute countryName is used for naming (entries of object class country - ed).
Table 3.4 lists the complete set of name forms that occur in the '93 Standard.
Table 3.4 The Standardised Name Forms.
| Name Form | Applies to this Structural Object Class | Attributes to be used in Naming (Abbreviation) |
| countryNameForm | Country | Country Name (C) |
| locNameForm | Locality | Locality Name (L) |
| sOPNameForm | Locality | State Or Province Name (SOP) |
| orgNameForm | Organisation | Organisation Name (O) |
| orgUnitNameForm | Organisational Unit | Organisational Unit Name (OU) |
| personNameForm | Person | Common Name (CN) |
| orgPersonNameForm | Organisational Person | Common Name (CN) |
| orgRoleNameForm | Organisational Role | Common Name (CN) |
| gONNameForm | Group Of Names | Common Name (CN) |
| resPersonNameForm | Residential Person | Common Name (CN)
optional - Street Address (SA) |
| applProcessNameForm | Application Process | Common Name (CN) |
| applEntityNameForm | Application Entity | Common Name (CN) |
| dSANameForm | DSA | Common Name (CN) |
| deviceNameForm | Device | Common Name (CN) |
DIT structure rules stop entries of the wrong (structural) object class from being placed in an inappropriate place in the DIT.
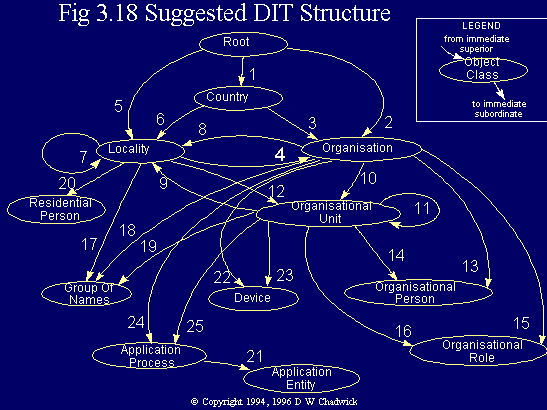
Figure B.1 from Part 7 of the '93 Standard is reproduced in Fig. 3.18. This shows a possible structure for the global DIT. It suggests which object classes should be superior to which other object classes. Each pair of superior/subordinate object classes are joined by a structure rule. Some examples of these structure rules are given in Fig. 3.19.
When I teach seminars on X.500, a common mistake that attendees make, is to confuse the object class hierarchy with the suggested DIT structure. The object class hierarchy e.g. as shown in Fig. 3.11 and Fig. 3.16 in which organisational person is a subclass of person, has nothing to do with the placement of entries in the DIT. It only controls which attributes an entry of a particular object class may contain. DIT structure rules control which object classes may be subordinate to which other object classes in the DIT. However these structure rules have nothing to do with controlling which attributes may be present in a particular entry. The two concepts are quite distinct, as shown in Fig. 3.21.
Fig. 3.18 Suggested DIT structure.
You can see that Fig. 3.18 suggests that only countries, organisations and localities may be subordinate to the root of the DIT (rules 1, 2 and 5). We have already seen many examples in this book of DNs starting with {C=GB...}. The Standard defines the DNs of all country entries via the country name form (Fig. 3.17), the DIT structure rule 1 (Fig. 3.19) and the country name attribute type (§ 3.4.1). As described in § 9.9, mechanisms now exist in many countries for organisations to obtain RDNs below their country nodes. Currently there is no standardised mechanism for allocating RDNs to organisations and localities beneath the root. Clearly many multi-national organisations would prefer to register beneath the root, rather than beneath each country, but this is not yet possible. Likewise, the use of a locality, such as {L=EU}, or {L=North America}, might be nice, but, to date, there is no international registration authority that can legitimately allocate these names. Therefore we currently have to be satisfied either with only registered countries beneath the root, or with unregistered multinational organisations and localities.
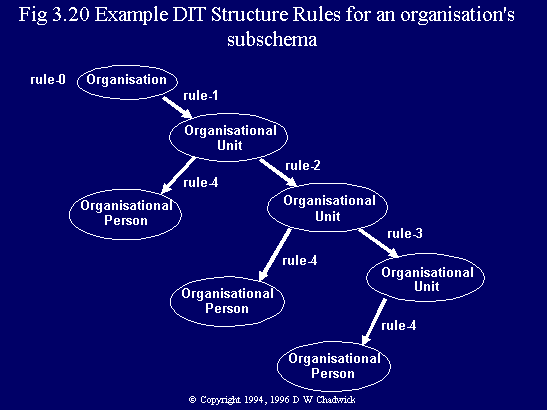
A common question asked about Fig. 3.18, is what is the meaning of an arrow that loops back to the same object class e.g. as in Locality and Organisational Unit, rules 7 and 11? The answer is that these object classes can appear underneath themselves in the DIT e.g. as in {C=GB, O=XYZ, OU=Production, OU=Plant A, OU=Maintenance}, so that the superior structure rule of a structure rule, is in fact itself. However, it is not recommended that a local subschema includes structure rules with this infinite recursion. A better way, shown in Fig. 3.20, is to exhaustively list the depth of the local DIT subtree.
Figure 3.19 lists a few DIT structure rule definitions from Annex B of Part 7 of the '93 Standard. These are the formal descriptions of some of the rules shown in Fig. 3.18. A structured English comparison is also presented. The '88 Standard consisted solely of the plain English sentence preceding the ASN.1 Information Object notation.
Remember that these rules are only exemplary, as it is not possible to standardise the structure of the global DIT.(This is why DIT structure rules have been given integer identifiers rather than object identifiers. The latter signify globally registered items of information.) Each DSA administrator is responsible for determining the actual DIT structure rules that are to control the placement of entries in their part of the DIT. A more restrictive set of definitions will be needed than those in Fig. 3.18. For instance, Fig. 3.18 allows structures of the type {C=GB, O=XYZ, OU=R&D, L=Birmingham, O=LMN}, as well as other bizarre structures, and infinite recursion.
The root is the immediate superior to entries of object class country.
sr1 STRUCTURE-RULE ::= {
NAME FORM countryNameForm,
ID
1 }
Structured English
DIT structure rule 1 is for
the Country Name Form.
There are no superior structure rules.
B.2 Organisation
The root, country or locality can be the immediate superior of entries of object class organisation.
sr2 STRUCTURE-RULE ::= {
NAME FORM orgNameForm
ID
2 }
sr3 STRUCTURE-RULE ::= {
NAME FORM
orgNameForm
SUPERIOR RULES {sr1}
ID
3 }
sr4 STRUCTURE-RULE ::= {
NAME FORM
orgNameForm
SUPERIOR RULES {sr5|sr6|sr7|sr8|sr9}
ID
4 }
Structured English
DIT structure rule 2 is for the Organisation Name Form.
There are no superior structure rules.
DIT structure rule 3 is for the Organisation Name Form.
The superior structure rule is rule 1.
DIT structure rule 4 is for the Organisation Name Form.
The superior structure rule is either rule 5, 6, 7, 8, or 9.
Structured English
DIT structure rule-0 is for
the Organisation Name Form.
There are no superior structure rules.
DIT structure rule-1 is for
the Organisational Unit Name Form.
The superior structure rule is rule-0.
DIT structure rule-2 is for
the Organisational Unit Name Form.
The superior structure rule is rule-1.
DIT structure rule-3 is for
the Organisational Unit Name Form.
The superior structure rule is rule-2.
DIT structure rule-4 is for
the Organisational Person Name Form.
The superior structure rule is either rule-1, rule-2, or rule 3.
The structure rules that control the DIT arcs between administrative authorities, for example, between a country's entry and an organisation's entry, are not described by any one subschema. These rules form the bridges between subschema administrative areas, and they have to be agreed by the participating parties. However, the subordinate party will need to add to its subschema a DIT structure rule for the autonomous administrative entry. This rule will state that there are no superior rules for this entry within this subschema. Rule-0 in Fig. 3.20 is an example of such a DIT structure rule. The superior party will also have to be prepared to link this entry into the DIT, below one of its entries. This linking is achieved via a hierarchical Operational Binding, as described in § 4.8.1 and § 9.9.
Fig. 3.21 depicts a small part of the DIT, comprising of just four entries. The diagram shows that the subschema component that controls the placement of entries in the DIT, one above another, is the DIT structure rule. One rule exists for each arc in the tree, and this will be specified by the DSA administrator (§ 3.13). DIT structure rules are based on name forms.
The RDN of an entry is controlled by the subschema component called name form. A name form is based upon the structural object class of the entry being named. The distinguished name of an entry is governed not only by its name form and its DIT structure rule, but also by those of its superior entries.
The contents of an entry are primarily governed by its structural object class. The subschema component object class specifies which attribute types an entry must and may contain. Each entry's object class (and its superclasses) are recorded in the values of its object class attribute. An entry's content may be further refined by an optional DIT content rule. This specifies additional attributes that must and may be contained in the entry, as well as those which must not be there. If the entry is a member of additional auxiliary object classes, then this is also controlled by the DIT content rule.
The semantics and syntax of an attribute's values are controlled by the attribute type definition. An attribute syntax is specified as an ASN.1 data type. Matching rules define how individual values of an attribute may be tested against user presented values to see if they match or not.
Fig. 3.22 Subschema for controlling collective attributes.
The collective attribute subentry contains three collective attributes, namely apple, tree and dollar. The tree attribute is to be included in entries of class circle, and the apple attribute is to be included in entries of class square. The dollar attribute is not present in any entries, and entries of class triangle do not contain any collective attributes, since there are no DIT content rules for either of them. One square entry does not contain the apple collective attribute, since the latter has been added to its collective exclusions operational attribute.
Table 3.5 The Directory operational attribute types
| Directory Operational Attribute | Purpose |
| Create Timestamp | Records when this entry was first created |
| Modify Timestamp | Records the last time this entry was modified |
| Creator's Name | The distinguished name of the user that created this entry |
| Modifier's Name | The distinguished name of the user that last modified this entry |
| Administrative Role | Signifies the type of administrative area associated with this administrative entry (Chapter 2) |
| Subtree Specification | Held in a subentry, to describe the associated subtree (Chapter 2) |
| Structural Object Class | Holds the structural object class of this entry |
| Governing Structure Rule | Points to the DIT structure rule that governs this entry |
| Collective Exclusions | Holds the list of collective attributes that are NOT to apply to this entry |
| Access Control Scheme | Held in an administrative entry. Used to identify the access control scheme in force in the ACSA (Chapter 8) |
| EntryACI | Holds the access controls that apply to this entry only (Chapter 8) |
| PrescriptiveACI | Held in a subentry, and contains the access controls to be applied to the entries described by the subtree specification (Chapter 8) |
| SubentryACI | Held in an administrative entry. Controls access to the subentries (Chapter 8) |
There is an additional set of Directory operational attributes that are used to define the subschema that is operative in an administrative area. These are known as the subschema policy operational attributes, and they are described in § 3.13.
The administrative role attribute is held in an administrative entry, and this controls which subentries are allowed to be subordinate to it. As described in § 2.11.2, the attribute has six allowed values. For example, if an access control value (inner or specific) is stored in the administrative role attribute, then there can be access control subentries beneath it.
Each subentry has an object class attribute (§ 2.12), and this controls which attributes can be placed in the subentry. One value of the object class attribute indicates that the entry is in fact a subentry, and is not a normal entry such as a person or a country entry. Other values indicate which type of subentry it is. Thus there are several different types of subentry object classes.
The distribution schema, and by this I mean the rules which state which distribution information can be held in a particular DSA Information Tree, has not been standardised. The distribution schema is entirely separate from the schema which controls the shape and content of the DIT. One component of the distribution schema that has been defined is the DSE type DSA specific operational attribute. This says which DSA shared and DSA specific operational attributes exist in a given DSE. At present there are no further plans to define more of the distribution schema.
Before performing a Directory update operation, DSA software should check the subschema in force, to ensure that the update operation will not violate any of the subschema policies. In this way users can be prevented from say, adding attributes to an entry that are disallowed by the entry's governing DIT content rule, or adding an entry with a RDN that violates the name form for its structural object class. Both '88 and '93 DSAs have to perform these checks. The only difference between them, is the way in which the subschema policy information is represented as being held. '88 DSAs did not have a standard way of representing this information, and each implementation will have specified its own proprietary way. '93 DSAs now have a standardised mechanism for holding the subschema information, as subschema policy operational attributes.
Table 3.6 The subschema policy operational attributes
| Subschema policy Attribute |
|
| DIT Structure Rules | Holds the DIT structure rules currently in force in the AA |
| Name Forms | Holds the name forms used by the AA |
| DIT Content Rules | Holds the DIT content rules controlling entries in the AA |
| Object Classes | Lists the object classes in use in the AA |
| Attribute Types | Lists the attribute types in use in the AA |
| Matching Rules | Lists the matching rules in use in the AA |
| Matching Rule Use | Lists the attributes types to which each matching rule can be applied |
The Directory system schema says how these policy attributes are to
be held, and this is, they must be held in the subentry of auxiliary
object class 'subschema'.
Note.Each subschema specific administrative area is only
allowed to have one subschema subentry.
However, the subschema policy attributes are logically present in all
the entries of the administrative area, implying that the subtree specification
attribute must take the default value of administrative area. (This
is similar to the way in which collective attributes appear to be
present in entries.) It is thus possible for a user to read the subschema
policy attributes from an entry, in the same way as they read the other
attributes that are held in the entry. For example, say a user reads some
user attributes from an entry in a remote DSA, and their local system does
not understand one of them. This could be because the attribute was defined
locally in the remote DSA (just as we did at Salford with the room number
attribute). The users or their administrator can then retrieve, from the
entry they just read, a copy of the 'attribute types' subschema policy
attribute value (w/w 3.9) that describes this unknown attribute type. This
retrieved subschema information can then be used to re-configure their
systems (DUAs and DSAs) to understand this new attribute type.
Of course, the subschema policy attributes can also be read directly from the subentry in which they live, but one would have to know either the name of the subentry, or how to search for it. This has been aided in two ways. Firstly, the Standard says that all subentries have a name form comprising common name = ..., and we know that they are immediately subordinate to the administrative point. Secondly, a subschema subentry has an auxiliary object class value of 'subschema subentry'. A third way was also proposed, but this did not make it into the Standard (w/w 3.8).
Each subschema policy attribute is multi-valued. Each value contains the definition of one instance of that component of the subschema. The definition consists essentially of two parts: an ASN.1 description of the subschema component, and a human readable description. So for example, if a particular organisation had 26 different attribute types in use throughout its administrative area, then the Attribute Types policy attribute would have 26 values, with each value describing one of the attributes. Each description would be in both ASN.1 and natural language. Both internationally standardised and locally defined attribute types would be in this list. (Seven of these values would describe the subschema policy attributes listed in Table 3.6.)
Subschemas evolve with time, as the needs of an organisation change. For example, new classes of object might need to be added, and old classes removed, or new DIT structure rules created to mirror the changes in the structure of the organisation. In order to cater for this, subschema policy attribute values can be replaced by new ones. Old values can be left in place, but marked obsolete. An administrator can then locate entries which conform to the obsolete subschema elements, and update them to conform to the new elements. The obsolete subschema values can then be deleted. Note that this does mean that at any point in time entries in the DIT may not conform to the subschema. As described earlier, entries cannot be added or modified, if such changes would violate the current subschema. However, subschema conformance is not checked when entries are read.
3.2 The reason for not mandating that auxiliary object classes were a subclass of top, was that some experts did not want them to inherit the mandatory 'object class' attribute from top. An object class that was a subclass of a structural object class and an auxiliary object class would then inherit this attribute twice. However, this already occurs with organisational person, which inherits the telephone number attribute from the person object class, and also has it defined in its MAY CONTAIN set. The Standard does not describe what happens when the double inclusion of an attribute type occurs in an object class definition. Clearly, a statement is needed that the attribute type should only occur once in instances of the class, and that an optional occurrence is overridden by a mandatory occurrence.
3.3 The use of the ASN.1 Macro notation for defining Directory schema components such as attribute types, attribute syntaxes and object classes, is only there as a documentation convenience, or shorthand. It would be perfectly easy to avoid using it, but it would mean that more words would have to be written for each definition. The Macro notation can concisely and unambiguously state certain, though not all, components of a definition. So for example, by using the ASN.1 Macro language for defining attribute syntaxes, one can concisely state what the ASN.1 type of the syntax is, what the object identifier for the attribute syntax is, what the value reference for the object identifier is, and which matching rules it supports. The Macro notation, as can be seen, is incapable of describing what the matching rules mean. We still have to resort to good old fashioned ambiguous natural language for this.
3.4 The ASN.1 Macro notation, defined in the '88 ASN.1 Standard, has been replaced by an Information Object Class notation in the '93 ASN.1 Standard. This is one reason why I have tried to avoid too much ASN.1 in this book. No sooner do you learn to use one shorthand language, than it is replaced by another one. The Information Object Class notation is again purely for the convenience of the Standard's writers, and could be replaced by natural language. Given the length of the natural language definitions of some of the matching rules, the shorthand Information Object Class notation for some of the definitions looks rather forlorn.
3.5 String ordering matching rules are controversial, since there is no internationally defined collating sequence to go with the Directory String syntax. So the ordering of characters on one computer may be different from the ordering of characters on another. Consequently these matching rules are not actually used by the Standard Attribute Types. Implementors will have to define attribute subtypes which incorporate the ordering matching rule.
3.6 Observant readers will note a subtle change of semantics between the matching rules of the '88 Standard, and those of the '93 Standard. The '88 Standard actually talks about matching two attribute values, whereas the '93 Standard talks about matching a presented value with an attribute value. Of course, the latter is more precise.
3.7 When matching rules and attribute syntaxes were combined in one '88 definition, the maximum size of presented strings and stored attribute string values was the same. With the separation of the definitions, we now have the slightly bizarre situation that a presented value (maximum size 128) can legitimately be bigger than the maximum allowed stored value!
3.8 A third method was proposed for locating the subschema subentry
that controls any given entry. Each subschema subentry holds an operational
attribute called governing subentry, whose value is its own distinguished
name. This attribute is then visible in all the entries of the subschema
administrative area, and so acts as a back pointer to the subentry.
Failure to standardise the 'governing subentry' operational attribute
does not prevent it from being used by individual implementations. It just
means that each implementation will need to separately define it, and allocate
its own object identifier to its definition. This is clearly less useful
than one internationally standardised operational attribute.
3.9 Simply reading the 'attribute types' subschema policy attribute would return all of its values, and there might be dozens of them. (Each value contains the description of just one of the attribute types known to the remote DSA.) By using a Search Base Entry operation, with an extensible filter item (w/w 5.8) quoting the equality matching rule and the object identifier of the unknown attribute type as the value to be matched on, and with the return matched values only indication set to True (§ 5.10), the user can ensure that only the desired policy value is retrieved, instead of all of the values. Subschema policy attributes have equality matching rules of object identifier first component matching rule (§ 3.3.5).
{kind=link}
{kind=link}
{kind=link}
{kind=link}