A third even more detailed abstract view looks inside a DSA to see how it functions. Both the internal processes and the data stored by the DSA are modelled. The DSA's data store, which contains part of the global DIT, is modelled as a DSA information tree. Each node in this tree is called a DSA Specific Entry, or DSE for short, as described in § 2.13. A DSA's internal processes, such as name resolution and operation evaluation, are described in terms of their interaction with the DSA's information tree. How this abstract DSA behaves, depends upon the service requested by the user (or by another DSA acting on behalf of a user) and also upon the contents of its own DSA information tree. However, the Standard stresses that how an actual DSA is implemented need bear no resemblance at all to this abstract model, as long as the externally visible behaviour, i.e. the abstract service, is identical to that of the abstract DSA. The Standard says nothing about the actual software components that will make up a real DSA. The building and design of a DSA are left entirely up to individual implementors, and this is how competition is introduced into standard conformant products. Some DSAs will be built using existing relational databases, others with existing hierarchical databases, and yet others with purpose built databases. Some DSA designs will outperform others, other designs may be more scalable, and yet other designs may be more flexible in the configuration tools that they give to administrators. The scope for DSA product differentiation is vast!
Implementors are free to design a DUA in any way that they please, and
are guaranteed that it will interwork with the Directory system as long
as it conforms to the DAP (Fig. 4.1).
Note. The Internet community has defined a Lightweight
Directory Access Protocol (LDAP) (Yeong et al., 1993) for DUAs, that is
now widely supported by implementations. For more details see § 10.3.1.
Fig. 4.1 Model of the Directory.
The Standard does not define the way that a DUA interacts with a user.
Remember that the user can be either a human or a computer application,
and so implementors are free to choose whichever design is most suitable
for the anticipated user. Some may choose a programmable interface, others
a command line interface, and others a windows, icons, mice and pointers
(WIMP) type interface. All of these currently exist, and the user must
choose the most appropriate one for their circumstances.
Note. Two programmable interfaces, using the C language,
exist. One has been defined by the X/Open group [9.1]. This interface,
known as XDS, provides a standard way of accessing a DUA implementation,
but is very complex. The other, defined by the Internet community is the
LDAP API, which is much easier to use.
It is very important to note that the user interface could bear very
little resemblance to the abstract service. Several interfaces currently
exist (Paradise International Report, 1991) in which a user enters a simple
request, which bears no resemblance to a distinguished name or any other
parameters of an abstract service request, and this is mapped into several
sequential abstract service requests (usually comprising of Searches, Lists
and Reads) before an answer is returned to the user. The average Directory
user may therefore need to understand very little about the Directory Abstract
Service or information models.
One thing that the Standard is very clear about, although this has caused a lot of confusion, is that there is precisely one DUA per user. A DUA is really a piece of software that conforms to the standardised interface between a user and the Directory system, i.e. the DAP. This does not mean, however, that each user must have their own personal DUA software. A piece of software on a computer, when invoked by one user, is acting as the DUA for that user. The same software, when invoked by another user, is acting as the DUA for that second user. So what, you may say. This distinction is important to bear in mind when one considers a topic such as caching and access controls. Data cached by shared DUA software on behalf of one user, cannot be given to a different user without potentially violating the access controls on the data. This is because the second user may not have access to the data, but since the DUA does not have a copy of the access control information, it cannot tell. However, data cached by a DUA can be returned to the user when the user requests it again. (The same is true of data cached by DSAs.) DUA and DSA designers need to be aware of this.
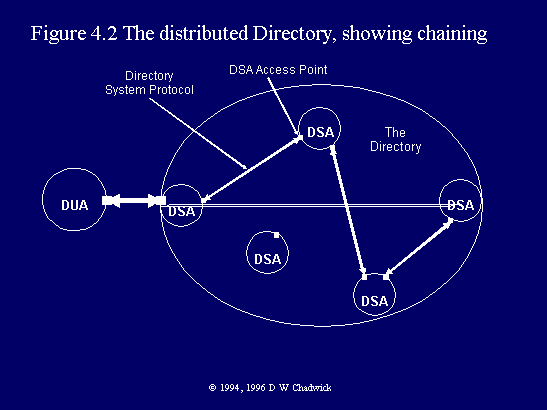
Fig. 4.2 The distributed Directory, showing chaining.
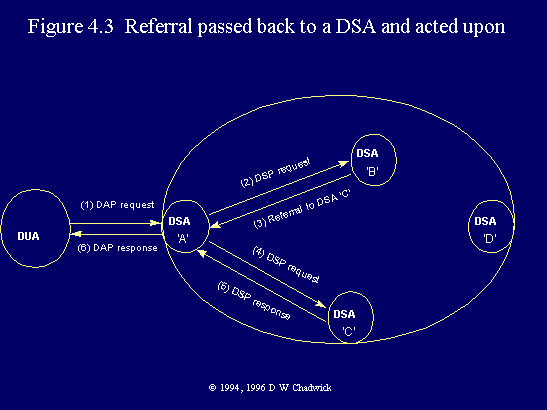
Fig. 4.3 Referral passed back to a DSA and acted upon.
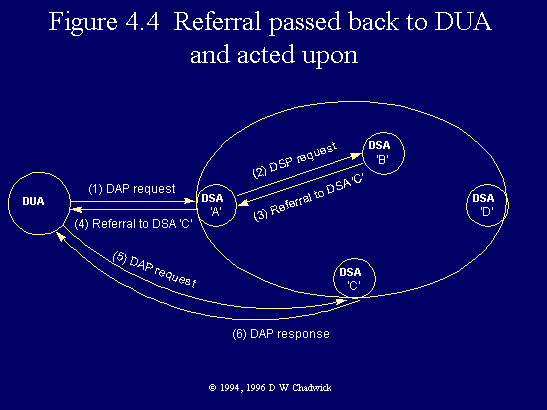
Fig. 4.4 Referral passed back to DUA and acted upon.
The major consequence of referrals is that distribution and location transparency are no longer possible. DUAs become aware that the DIT is distributed between different systems. They also become aware of the actual location of the information. Referrals tell them what information is likely to be stored where. This does have major benefits however. Firstly, it can be much more efficient for DUAs to directly contact the DSA where the data is actually held, rather than always going via its home DSA (§ 4.3). Secondly, under some security regimes, administrators may require DUAs to directly Bind (§ 4.6.1) to their DSAs rather than sending them information which will be chained via several, possibly untrustworthy, DSAs. Note however that both of these advantages require configurable DUA software, that allows new DSA Access Points to be configured in and selected by the user.
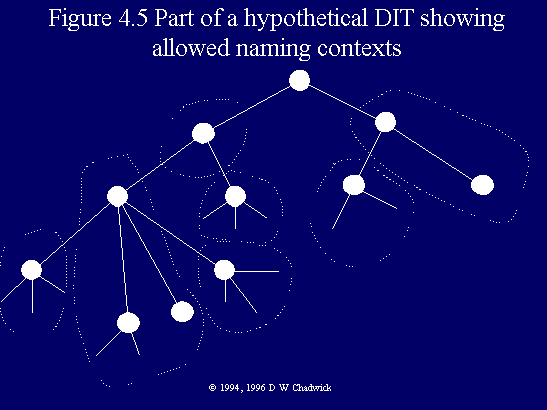
Fig. 4.5 Part of a hypothetical DIT, showing allowed naming contexts.
The way that the DIT is actually distributed amongst DSAs is very simple in concept. The global DIT is partitioned into subtrees, as decided by local administrators. A subtree can be of arbitrary size, ranging from a single entry, to the entire DIT. The important thing to note though, is that every partition must be a true subtree, and cannot be portions of the DIT with holes in it, i.e. entries missing from the middle of a large subtree. (Figs 4.5 and 4.6 show the partitioning of a hypothetical DIT into allowable and disallowable subtrees.) Each subtree must reside within one DSA. It cannot be distributed between two or more DSAs, without first splitting it into two or more subtrees. Each DSA can hold any number of subtrees. (In this way it is possible for a DSA to hold whatever parts of the DIT that it wishes, including the disallowed subtrees shown in Fig. 4.6. All that is needed to be done is to split the disallowed subtrees into several true subtrees.) Subtrees must always be maximal. In other words, a DSA may not hold two subtrees which are vertically adjacent to each other in the DIT, but rather it must hold one maximal subtree.
Fig. 4.6 Part of a hypothetical DIT, showing illegal naming contexts.
Each of these subtree partitions has an entry at its root, and the distinguished name of this entry is called the context prefix of the subtree. Obviously, all the entries in a subtree will have the context prefix as the initial part of their distinguished names.
Associated with each subtree, are a set of knowledge references. These knowledge references point to the DSAs which hold the subtrees vertically adjacent to this one. Knowledge references are the distribution meta-information held by DSAs. For a subtree that does not start at the top of the DIT, there will be one immediate superior knowledge reference associated with it. This points to the DSA holding the subtree that is immediately above it in the DIT (w/w 4.2). Subtrees that start at the top of the DIT are special, and obviously cannot have an immediate superior reference. They are held in special DSAs called First Level DSAs, and these will be described later in § 9.7. For a subtree that is not at the bottom of the DIT i.e. it does not have only leaf entries at its lower extremities, there will be a set of subordinate knowledge references which point to the DSAs holding the subtrees immediately beneath it. Fig. 4.7 shows the subordinate and immediate superior knowledge references associated with the subtrees of Fig. 4.5. It can be seen that these are linked together in pairs, and point to each other's DSAs. This linkage is part of the hierarchical Operational Binding between the pair of DSAs (§ 4.8.1).
Fig. 4.7 Part of hypothetical DIT, showing hierarchical Operational Bindings.
The combination of a subtree of entries, a context prefix, a full set of subordinate references (which can be empty) and possibly an immediate superior reference, is called a naming context. Naming contexts, then, are the complete unit of distribution of the DIT amongst DSAs. They comprise of a subtree of DIT entries and its associated distribution meta-information.
Organisations running their own directory service, might typically start off with one DSA. This will hold the naming context for the whole organisation i.e. a context prefix of {C=XX, O=OrgName}, with the naming context extending down to all of the leaves. As the organisation grows, it might split the naming context into several smaller ones, one for each functional unit of the organisation (sales, manufacturing, admin etc.), with each new naming context being placed in a new DSA physically located in each of the functional units. The naming context holding the organisation's entry, will now need to have subordinate references to each of the functional unit DSAs. Each of the functional unit DSAs will need to have an immediate superior reference to the DSA holding the organisation's naming context. Hierarchical Operational Bindings are the concept designed to keep these references synchronised.
In order to facilitate distributed name resolution, each non First Level DSA must hold one superior reference. This reference points upwards in the DIT, effectively to the root of the DIT. (It actually points to any DSA that holds any naming context which is nearer to the root of the DIT than all of those that it holds.) In many cases superior references will point to First Level DSAs. In the DSA information tree, a superior reference is held in the root DSE (Fig. 9.2).
In the absence of cross references (§ 9.2.5), distributed name resolution proceeds up the DIT, via superior or immediate superior references, until either a First Level DSA, or a DSA holding a naming context with a context prefix that matches an initial part of the purported name, is encountered. At this point, distributed name resolution then proceeds down the DIT via subordinate (or non-specific subordinate - see § 9.2.3) references, until the DSA holding the required entry is encountered. Only after distributed name resolution starts to move down the DIT, is it possible to know if a purported name is erroneous. (From this you will deduce that First Level DSAs have to know about all the naming contexts that start immediately below the root, i.e. typically those with context prefixes of {C=XX}.)
Once a non First Level DSA knows the names and addresses of:
Name resolution usually is no more complex in the presence of replication,
than without it - we just have in built redundancy.
Note. This is not always the case when non-specific
subordinate references are present - see § 9.13.16.
If the first DSA contacted via its Access Point is not available, then
another Access Point from the set can be chosen. What is more complex however,
is the updating and distribution of these sets of Access Points between
the referencing DSAs. Hierarchical and shadow Operational Bindings were
designed partially with this in mind, and it is the Operational Binding
management protocol that may be used to keep this information up to date.
This will be described fully in § 6.4.2, § 9.5 and § 9.19ff.
In order to establish the connection, certain information is needed, such as: an identification of the protocol that is to be used (i.e. DISP, DAP, DSP or DOP, in this case it is the DAP), the names and addresses of the communicating parties, and security credentials that enable the parties to authenticate each other. These are all parameters of the Bind operation. Once the connection has been established, then the user may interrogate or modify the information stored in the Directory.
When the user has finished accessing the information in the Directory, the connection is closed with the Unbind operation. The Unbind message contains no parameters.
The Read Operation
The Read operation is used to read information from one specific directory entry. The input arguments are a purported name and an indication of which information is to be read. The latter argument enables the user to specify whether all the information is to be read, or just a subset of the attribute types and values held in the entry.
The result of the operation normally yields the distinguished name of the entry, plus the requested attribute types and values.
The Compare Operation
The Compare operation is used to compare a user presented attribute value with those actually existing in the entry. The input arguments are a purported name, and a purported attribute value. The operation result returns a True or False indication, signifying whether or not the attribute value is actually present in the target entry. Compare is usually used to check the value of the user password attribute (Chapter 7).
The List Operation
The List operation is used to list the immediate subordinates of an
entry. The input argument is a purported name. The result of the operation
returns the relative distinguished names of the subordinates. The List
operation is used to browse through the DIT, and to discover which entries
are below other entries in the DIT, for example, to find the names of all
the people resident in an organisational unit.
Note. Under certain circumstances (§ 5.8),
the list may be incomplete. In this case, embedded referrals to other DSAs
will be returned in place of the names of the subordinates.
The Search Operation
The Search operation is used to search portions of the DIT, and to return selected information about selected entries. It is potentially a very powerful operation, and allows users to find entries that match a chosen set of criteria. The input arguments identify amongst other things: the base entry from which the search is to start, the portion of the DIT to be searched, the criteria (filter) for selecting entries, and what information should be returned from the selected entries.
The base entry argument is a purported name. The portion of DIT to be searched may be one of: the base entry only, or only the immediate subordinates of the base entry, or the base entry plus its entire subtree. The filter applies certain tests to an entry to determine if it is selected or not. The tests are applied to attributes within the entry, and test for such things as: if an attribute type is present, or if an attribute value lies within a given range. Finally, how much entry information should be returned is specified. This can be all the information, or just a specified subset of attribute types and values.
The result returns the name of every selected entry along with the requested entry information. Under certain circumstances (§ 5.10.3), the result may be incomplete. In this case, embedded referrals to other DSAs will be returned in place of the names of the entries.
The Abandon Operation
The Abandon operation allows the user to abandon any of the above interrogation operations, if they are no longer interested in obtaining the result. The abandon operation has just one argument, which identifies the operation to be abandoned. If the abandon operation succeeds, the operation that has been abandoned will return an error diagnostic instead of a normal result. However, the abandon operation is not guaranteed to always work, and the Directory may refuse (fail) the abandon request, e.g. a DSA may not wish, or be able, to abandon an operation which has already been chained to other DSAs. In this case the original operation will complete as normal, and the abandon operation will return an error.
Successful modify operations return a null result.
The AddEntry Operation
The AddEntry operation allows a leaf entry to be added to the DIT. The
DIT is thus built up from the root of a naming context, downwards.
Note that this is the standardised method of building
the DIT. Most Implementations add proprietary interfaces for bulk loading
the DIT from other corporate databases.
Entries cannot be inserted into the middle of a branch, since this
would affect the distinguished names of all of the subordinate entries.
(Note however, that the ModifyDN operation affectively allows non-leaf
insertions and deletions.)
The operation arguments contain the name of the new entry (distinguished name in '88 edition systems), plus its associated attributes. Any type of entry may be added: an object entry, an alias entry or a subentry.
The RemoveEntry Operation
The RemoveEntry operation allows a leaf entry to be deleted from the Directory. The operation argument contains the distinguished name of the entry to be removed. Any type of entry may be removed, but in order to remove a non-leaf entry, all its subordinates have to be removed first. In this way the tree is eaten away leaf by leaf.
The ModifyRDN Operation
This operation, which is only available to '88 edition systems, is used to change the relative distinguished name of a leaf entry. The operation arguments are the distinguished name of the entry, the new RDN, and an indication of whether or not the old RDN attribute values should be deleted from the entry. ModifyRDN provides no capability for restructuring the DIT. '88 edition DSAs will have to provide this facility via a proprietary mechanism.
The ModifyDN Operation
The ModifyRDN operation obviously has many restrictions, for example, how do you rename a non-leaf entry? Consequently, its scope has been considerably enhanced in the '93 Standard, and it has been given a new name to signify this difference. The ModifyDN operation is capable of renaming leaf and non-leaf entries, and of moving subtrees to new positions in the DIT. The operation can therefore help in restructuring the DIT to reflect new organisational structures.
The operation arguments comprise of the distinguished name of the entry to be renamed, the new RDN, and the distinguished name of the new superior entry in the DIT (optional). The standard places restrictions on the operation when it is used to move subtrees. In this case, all the affected entries must be in the same DSA (§ 5.16), otherwise proprietary mechanisms will still be needed.
The ModifyEntry Operation
This operation allows the contents of an entry to be modified, by adding new attributes and attribute values to, and by deleting existing attributes and attribute values from, the entry's contents. Any number of modifications may be specified in one operation, but all must succeed, or none will be made. In other words, the operation is atomic. Note that you are not allowed to modify the distinguished attribute values (i.e. the RDN) of the entry by this operation.
The operation arguments are the name of the entry to be modified, plus the sequence of modifications to be made.
The operations that flow between the DSAs are termed chained operations. Each of the DAP operations has a corresponding DSP chained operation, and each result has a corresponding chained result.
The mapping of an operation to a chained operation is very simple - add some Chaining Arguments to the arguments of the DAP operation. The Chaining Arguments basically contain information about the progress of the evaluation of the operation (so-called state information) that is needed by the next DSA in the chain, in order for it to correctly process the request (w/w 4.1). Optional security and local information may also be passed in Chaining Arguments between a pair of DSAs. These Chaining Arguments are described more fully in Chapter 9.
The mapping of an operation result to a chained operation result is also very simple - add chaining results arguments to the arguments of the operation result. This information, which is minimal, and is often absent, may carry security or other local information between a pair of DSAs.
Finally, the mapping of chained errors to operation errors is even more simple - they are identical. Once a DSA returns an error to an operation, it is normally not manipulated in any way by any of the DSAs in the chain between the DSA signalling the error, and the DUA receiving it. The DSAs simply pass the error, unaltered, back to the DUA. The only exceptions to this are that certain soft errors (§ 9.12) may be ignored by a DSA, and that referral errors may be processed or manipulated. Certain soft errors - such as busy or unavailable - may be ignored by a DSA if it has another Access Point to contact instead of the one that failed - this may be the case when parts of the DIT are replicated. On the other hand, hard errors such as entry does not exist are never ignored. A referral has, quite anomalously, been classified as an error in the Standard, whereas it really is a result indicating partial progress of a request. As mentioned in §4.2, referrals may be processed by DSAs, so that they are not returned to the user. Also, as described in w/w 4.1, DSP referrals and DAP referrals are slightly different, in that referenceType is missing from '88 edition DAP referrals. An '88 home DSA therefore needs to alter a referral before passing it to the DUA.
The '88 edition of the Standard did not mention Operational Bindings by name, although they were implicit since it was obvious that '88 DSAs had to co-operate. The only difference between the two editions of the Standard in this respect, is that the '93 Standard explicitly details, for the two standardised types of Operational Binding, the information that needs to be exchanged between the co-operating DSAs. It also defines an optional protocol - the Directory Operational Binding Management Protocol (DOP) - that may be used to create and maintain this information. On the other hand, the '88 Standard assumes that this information appears in a DSA as if by magic. From the perspective of the '93 Standard, '88 DSAs do have Operational Bindings with other DSAs, but the requisite information appears in the DSA via proprietary means. This probably means that phone calls or Email message are exchanged between the administrators of the two DSAs, and that configuration information is input into each DSA via a proprietary management interface. '93 DSAs that do not support the DOP will also have to resort to these proprietary means for inputting and updating their Operational Binding information.
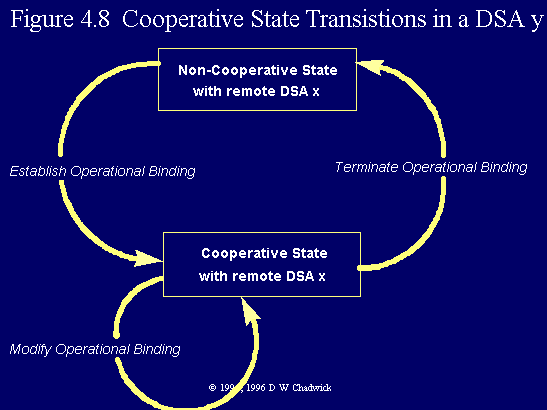
Five operations make up the Operational Binding management protocol. The DSA Operational Binding Management Bind operation (DOP Bind for short) is used to open up an association (or connection) between two DSAs, so that they may establish or update an Operational Binding (Fig. 4.10). The Establish Operational Binding operation creates an Operational Binding between a pair of DSAs, and transfers the appropriate information between each DSA, so that they know how to cooperate. DSAs which do not have an Operational Binding between them, are in a non-co-operative state, and can quite properly refuse any operation that passes between them. DSAs that have an active Operational Binding are in a co-operative state, and should correctly process any operation that passes between them, providing of course that it is an operation that was expected under the terms of the relationship. Figure 4.8 shows the state transitions that occur in a DSA, as a result of receiving DOP operations from another DSA.
Fig. 4.8 Co-operative state transitions in a DSA y.
The Modify Operational Binding operation may be used by either DSA to update the operational information stored by the other DSA, and to thereby change the parameters of the relationship. Examples here include: a DSA is re-configured to a new address, or the context prefix of a naming context changes, or a shadowing DSA no longer requires a copy of certain attributes. The Terminate Operational Binding operation cancels the relationship between the pair of DSAs, and causes the stored operational information to be deleted.
Finally the DSA Operational Binding Management Unbind operation is used to close the connection after the two DSAs have finished updating their Operational Binding information. The Operational Binding will still be active after the Unbind operation, unless of course, a Terminate Operational Binding message was transferred.
Hierarchical Operational Bindings
We have seen that the DIT is distributed between DSAs and that each
DSA holds some knowledge information that tells it where its portion of
the DIT (naming context) fits into the global DIT. This immediate superior/subordinate
reference pair forms part of the operational information of a Hierarchical
Operational Binding, see Fig. 4.7. However, there are more to HOBs than
simple knowledge reference synchronisation. Certain of the information
in the global DIT, i.e. that associated with subentries, applies to subtrees
of the DIT, irrespective of how the subtrees are distributed between DSAs.
(This information is part of the Directory Operational and Administrative
Information Model, described in Chapter 2.) If a DIT subtree is distributed
between a pair of DSAs, i.e. a DIT subtree consists of two adjacent naming
contexts held in different DSAs, then the subentry information held in
the (superior) DSA holding the administrative entry, needs to be copied
to the (subordinate) DSA holding the lower part of the subtree. For example,
the collective telephone number attribute may be held in a subentry below
the organisation's entry (the administrative entry), but it may apply to
all the entries below the organisation's entry. Some of these entries may
be held in other DSAs (e.g. see Fig. 5.3). The creation of an immediate
superior knowledge reference and subentry information in the subordinate
DSA, and a subordinate knowledge reference in the superior DSA,
signifies the creation of the Hierarchical Operational Binding between
the pair of DSAs. Each DSA now knows how to behave in respect of the other
DSA, and knows how and when to chain or refer a user's request to the other
one. The subordinate DSA also knows which access controls, schema information
and collective attributes it has inherited from its immediate superior
DSA.
Note.The Standard also defines a Non-specific
Hierarchical Operational Binding (NHOB), which is established when the
immediate superior DSA has a non-specific subordinate reference instead
of a subordinate reference to the subordinate DSA. In most other respects,
NHOBs are similar to HOBs.
Fig. 4.9 An example of DOP and DSP requests interleaved in time.
When a new non First Level DSA is created, in order for it to connect
to the wider Directory, it first needs to establish a Hierarchical Operational
Binding with its immediately superior DSA. This links it into the DIT,
passes it down administrative information (if any) from its superior, gives
it an immediate superior reference (which can also be used as a superior
reference), and provides the superior with a subordinate reference (see
§ 9.9 for more details). DSP operations may then flow between the
two DSAs. This is illustrated in Fig. 4.9. The subordinate DSA holds the
naming context with context prefix {C=US, L=Florida, O=XYZ Inc, OU=Sales}.
The immediate superior DSA holds the naming context with context prefix
{C=US, L=Florida, O=XYZ Inc}. The subordinate DSA establishes a HOB with
its superior, and both DSAs are then ready to co-operate.
Note.The superior DSA is also able to initiate
the Establish Operational Binding operation. It does not matter which of
the two DSAs actually initiates the request.
(Remember that this information could flow via a telephone call and
be manually configured into both DSAs, instead of using the automated DOP.)
Both DSAs then pass DSP requests between themselves as and when necessary
e.g. the subordinate DSA asks to read an entry from Texas. The subordinate
DSA is then due to be re-configured on the network, causing it to change
addresses. It notifies the immediate superior DSA, via a Modify Operational
Binding request, that as of 8 a.m. Monday morning it will have a new address.
Both before and after the re-configuration, the superior DSA is able to
contact its subordinate DSA, and user requests can still flow between them
via the DSP e.g. the superior DSA wants to search for information from
the sales unit. Management then decide to implement a tighter security
policy, and place some mandatory access controls over the whole organisation.
They do this by updating the prescriptive access controls in the organisation's
administrative subentry. This information is automatically conveyed to
the subordinate DSA via the DOP (Modify Operational Binding request). User
requests may continue to flow undisturbed between the two DSAs, both before
and after the Operational Binding update.
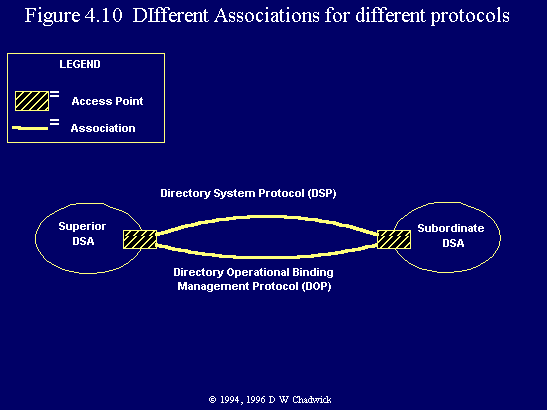
Fig. 4.10 Different associations for different protocols.
Note that whilst the DOP and DSP requests are interleaved in time, they do not flow down the same connection (or association). Both the DSP and DOP requests have to be superseded by an appropriate Bind operation. This establishes an association for the particular protocol (or application context). Figure 4.10 illustrates the fact that two separate logical communications links are established between the pair of DSAs, one for each protocol, with each link using the same set of DSA Access Points.
Shadow Operational Bindings
The second type of Operational Binding is concerned with replication. DSAs are able to copy DIT information to one another. This mechanism, known as shadowing, is described in more detail in Chapter 6. Before a DSA is able to participate in shadowing, it needs to establish the terms of the operational relationship with the other DSA. This information comprises of such things as: the portion of the DIT that is to be copied, and the frequency that updates should be transferred between the DSAs. Hence another type of Operational Binding is the Shadow Operational Binding (SOB). Before replication (shadowing) can take place, a Shadow Operational Binding needs to be established between two DSAs. One of the DSAs, called the shadow supplier, will provide the replicated information to the other DSA, called the shadow consumer. Once the Operational Binding has been established, either by proprietary means, or by using the DOP, shadowing proper can take place, using the Directory Information Shadowing Protocol (DISP) (§ 4.9).
The terms of the shadowing agreement may be updated at any time via the Modify Operational Binding message, and subsequent DISP messages will then abide by the terms of the new agreement. When shadowing is to cease, a Terminate Operational Binding message is sent, after which no more DISP messages are allowed. The sequencing of DISP and DOP messages is very similar to those of the DSP and DOP shown in Fig. 4.9. Two associations are also needed, one for the DOP and one for the DISP, similar to that shown in Fig. 4.10. If a pair of DSAs had a HOB and a SOB, then three associations would be needed, one each for the DOP, DISP and DSP.
One of the functions of the SOB is to update a supplier DSA with the list of DSAs that have been provided with copies of the naming context. (DSAs receiving copies may also act as suppliers, and pass the data onto other DSAs, see Fig. 6.1.) In this way the DSA holding the master copy of a naming context is able to obtain a complete list of the Access Points of all of the DSAs holding shadow copies of the naming context. This information can then be added to the set of knowledge references that point to a particular naming context, thereby building in redundancy to name resolution. A complete description of this mechanism is given in § 9.5.
The Coordinate Shadow Update operation tells the consumer which batch of updates it should have received last time round, and also what sort of update it will receive this time. The latter parameter, called the update strategy, takes one of three values:
The shadow consumer can either reply OK to the operation, in which case it is prepared to receive the next batch of updates as specified, or it can send an error response with a diagnostic code such as: I am not ready to receive updates yet, or I already have that batch of updates safely stored.
The Request Shadow Update operation tells the supplier that the consumer is ready to receive a batch of updates. The parameters are the same as in the Coordinate Shadow Update operation, i.e., the timestamp of the last batch of updates that were successfully received, and the sort of update that it would like (obviously no updates is not allowed in this case!). If the shadow supplier is willing to send the next batch of updates by return, it will send an OK response to the operation, otherwise it will send an error response with a diagnostic code such as: I am not yet ready to send updates, or I do not support that sort of update strategy.
Assuming that the two DSAs have been successfully synchronised by either the Coordinate or Request Shadow Update operation, the shadow supplier will then send an Update Shadow operation to the consumer. This operation provides the latest batch timestamp, and either lists the changes that have been made to the replicated portion of the DIT since the last update, or sends a completely new copy of the data to the consumer, depending upon the update strategy. The shadow consumer securely stores the updates, and then replies OK to the supplier (Fig. 4.11). Alternatively, the consumer may indicate a problem with the received data, and may return an error code. Unfortunately the Standard gives few guidelines as to how to proceed if an error occurs during an Update Shadow operation (w/w 6.4).
Fig. 4.11 The sequencing of the DISP.
Once the shadowed data has been securely stored, it may be used to satisfy user queries in just the same way as other data mastered by the consumer DSA. The main difference is that user modify requests cannot be performed on the shadowed data. These must always be sent to the master DSA. Their effects on the shadowed data will be received some time later by the consumer DSA when it receives the next batch of shadow updates.
4.2 Naming contexts originally started out containing a reference, as well as a set of subordinate references. The superior reference points upwards in the DIT, to any DSA which is superior to it in terms of its DIT holdings. It was realised however, that if a DSA holds more than one naming context, then it will hold more than one superior reference. All of these except one, will be redundant in the process of name resolution, since all point upwards towards the root of the DIT. Only the one that points highest need be kept. (Subordinate references, on the other hand, are never redundant, because they all point to different subordinates.) It was thus decided in the '88 Standard to remove superior references from naming contexts, and to say that DSAs have only one superior reference, irrespective of the number of naming contexts held. This superior reference must point to a DSA which holds a naming context superior in the DIT to all of the naming contexts held by this DSA. When the '92 work was started, and hierarchical Operational Bindings were introduced, it was again realised that a superior reference was needed per naming context. So they were introduced again into naming contexts, only this time they were given the name immediate superior reference, to differentiate them from the one and only superior reference. Furthermore, an immediate superior reference does not point to the root of the DIT, but instead points to the DSA holding the immediately superior naming context.
4.3 The term actually used in the Standard for the information held by a DSA pointed to in a shadow reference, is commonly usable copy. This term is really a fudge to cover up a disagreement between the experts. Some experts suggested that shadow references should only be to DSAs that held complete copies of whole naming contexts, whilst others suggested that they could be to any DSA that held a copy of any useful part of a naming context. But with the latter position, if the shadow reference was to be of significant use to a wide audience, it would also need to hold an indication of precisely which part of the naming context was held in the remote DSA. No-one wanted to go down this path, and so the compromise was to say that shadow references point to commonly usable copies of a naming context. The precise definition of what commonly usable actually means is left to Directory administrators. The Standard only recommends that they should be copies of whole naming contexts.
4.4 It is possible to build a DSA that only holds a superior reference and that does not hold any naming contexts or shadowed information. Each DUA request to it would then be chained to the superior DSA. Such a DSA would really be a DUA that talks the DSP!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}