The parameters of the List operation are shown in Table 5.13. The purported name may be the name of any entry in the DIT, including the root and aliases. Obviously if the named entry is a leaf entry, then the result will be an empty set of subordinates.
Table 5.13 The parameters of the List Argument
| List Arguments | Defined in |
| The purported name of the entry whose subordinates are to be listed | 5.6 and 5.8 |
| *Requesting Paged Results | 5.9 |
| Common Arguments | 5.4 |
Table 5.14 The parameters of the List Result
| List Result | ASN.1 Parameter Encoding |
| The distinguished name of the target entry whose subordinates are listed | DistinguishedName OPTIONAL |
| Information about the subordinates.
For each subordinate: Its relative distinguished name Whether it is an alias or not Whether the information came directly from the subordinate entry or not |
SET OF SEQUENCE { RelativeDistinguishedName BOOLEAN DEFAULT FALSE BOOLEAN DEFAULT TRUE} |
| If this is not the complete set of subordinates, then why not | PartialOutcomeQualifier OPTIONAL |
| Common Results | see § 5.5 |
| Additional uncorrelated List Results that have been digitally signed by other DSAs | SET OF ListResult |
Information is returned about every subordinate of the entry that the processing DSA holds, and that the user has permission to know about (Chapter 8). This information consists of the relative distinguished name of the subordinate, a flag which indicates if the subordinate entry is an alias entry or not, and another flag indicating whether the information was read from the actual subordinate entry or from a shadow or other copy of it.
The majority of List operations will be completely processed by the DSA holding the target entry, and the List result will only consist of the above two parameters together with Common Results.
In a few situations this will not be the case. This will be when either the locally generated result is too big, or when one or more of the subordinates of the entry are located in other (subordinate) DSAs and the executing DSA is not willing or able to chain the request to them. A partial result is returned to the user, and the partial outcome qualifier describes why the result is not complete (§ 5.8.2).
If subordinates are located in other DSAs, then the executing DSA may chain the request to them. If the subordinate DSAs reply with unsigned answers, then these will be merged with the locally generated set of subordinates to form a complete answer for the user. If however, one (or more) of these subordinate DSAs returns a digitally signed List result, these cannot be merged with the local result without invalidating their signatures (Chapter 7). They have to be appended to the local result as a set of uncorrelated List results.
If subordinates are located in other DSAs, but the user is prepared to accept copy information (§ 5.4.1), then the DSA may not need to chain the request. If the DSA has the complete HOB information provided by the subordinate DSA, then the subordinate entry information can be generated locally. This is because a HOB provides the superior DSA (in this case the DSA processing the List operation) with the name of the subordinate entry, and optionally with the access control information and the alias flag and object class information governing the subordinate entry (§ 9.20.3). This enables the superior DSA to generate the complete set of information about the subordinate, and to flag it as being not from the entry.
If either the time or size limit set by the user, or the local administrative limit set by the administrator of the processing DSA, is exceeded, then the DSA will return an arbitrary subset of results. The DSA will warn the user that the result is incomplete by setting the appropriate limit flag.
If the DSA did not chain the request to subordinate DSAs (where these existed) then pointers to these DSAs are returned in the result. These pointers, called continuation references, allow the DUA to continue processing the request in order to get a complete set of results for the user. Continuation References are syntactically identical to DAP referrals (§ 9.13.1), and are used in the same way. The XDS API includes an option to allow automatic processing of continuation references by the DUA, so that they never need be passed back to the user application.
Table 5.15 The parameters of the Partial Outcome Qualifier
| Partial Outcome Qualifier Parameter | ASN.1 Parameter Encoding |
| The result is too big and has exceeded this limit | INTEGER (0=time limit,1=size limit, 2=administrative limit) |
| The following subordinate DSAs were not contacted | SET OF Continuation References |
| A subordinate DSA has not implemented a critical extension | BOOLEAN DEFAULT FALSE |
| *A subordinate DSA has returned an unknown error | SET OF Errors |
| *There are still one or more pages of results to come | OCTET STRING |
If the DSA did successfully chain the request to a subordinate DSA, then one of two things could happen. The subordinate DSA could successfully continue processing the request, and return a result to the superior DSA, or it could fail in some way, and return an error. In the former case a partial outcome qualifier would not be generated by the superior DSA (either a merged result or an uncorrelated set of signed results would be produced). In the latter case, the failure (of a Search sub-query) could be because the subordinate DSA does not support a '93 extension which was marked by the user as being critical e.g. access subentries only. In this case the error diagnostic returned by the subordinate DSA would be Service Error (Unavailable Critical Extension). The superior DSA should then set the BOOLEAN in partial outcome qualifier to True, in order to warn the user of this fact. (Note that this error cannot occur for List operations.)
The '93 parameter which warns of an unknown error being returned, will currently never be set, since no new (chained) errors have been defined in the '93 Standard.
Note. The only new error is Service Error (invalid query reference) and this is only sent from the home DSA to the DUA.
The parameter has been added in order to allow subsequent editions of the Standard to be able to define new error codes if the need arises.
Finally the octet string, called the query reference, is used to signal that another page of results is still waiting to be returned. This is described more fully in § 5.9.
Note that with the List operation, we cannot actually specify that only people should be listed. We will actually get all the subordinates, whatever they are. To only list people, we would have to use a Search operation, of one level, and filter on organisational person object class.
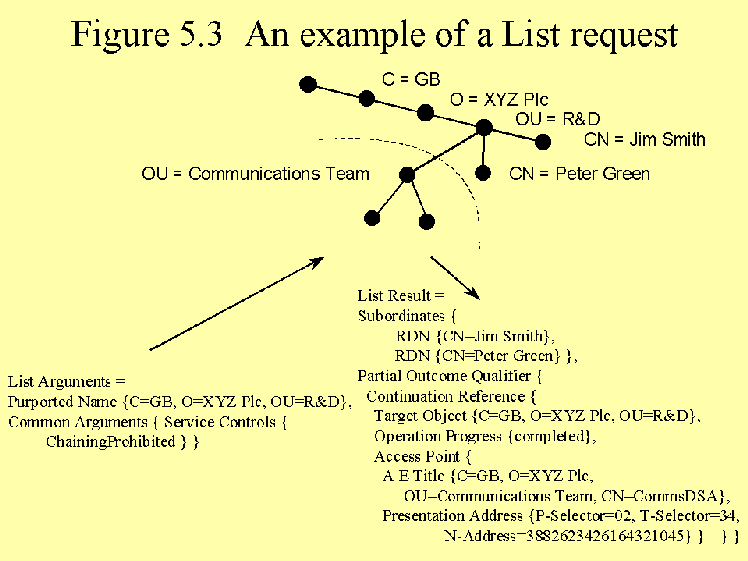
Suppose that we are happy with copied information held by our local DSA, and we do not want to pay for any chained operations. Fig. 5.3 shows the parameters that need to be sent in the List request.
Fig. 5.3 An example of a List Request.
Suppose that our local DSA holds entries for all of the people directly in the R&D unit, and that these are returned in the List result (for the purpose of this example we assume that there are only two such people). Suppose further that the R&D unit contains a specialised group who are referred to as the Communications Team, and that their DIT entries are below the node {C=UK, O=XYZ Plc, OU=R&D, OU=Communications Team}. However, this node and all its subordinate entries are held in a DSA belonging to the Communications Team. Suppose that our local DSA only holds a subordinate reference to this DSA, and does not have all the optional information of the HOB. Our local DSA is therefore not able to return the name of this node in the List Result, but rather must return a continuation reference to the Communications Team's DSA. The continuation reference tells us the name and address of the DSA to contact (Access Point), the name to be used in the List request to be sent to it (Target Object), and the state information to control the processing of the request by that DSA (Operation Progress). If, on the other hand, our local DSA had held the optional HOB information, the List Result could have contained the name of this third subordinate - OU=Communications Team - along with the from entry boolean set to False, and a continuation reference would not have been included.
Table 5.16 The parameters of a Paged Results Request
| Paged Results Request Parameter | Parameter Contents | ASN.1 Parameter Encoding |
| either
New Request |
Page size Sort Keys Sort in reverse order flag Sort before merging flag |
INTEGER SEQUENCE OF Attribute Types BOOLEAN DEFAULT FALSE BOOLEAN DEFAULT FALSE |
| or
Continued Request |
Query Reference |
OCTET STRING |
Support for the paged results service is optional, and even if supported, DSAs are not obliged to support any particular set of sort keys. The paged results service can only be offered by the home DSA, and the paged results parameters are not carried in the DSP.
When the first page of results is returned to the DUA, it will normally include a query reference OCTET STRING in the partial outcome qualifier. This indicates to the DUA that a further page of results is waiting to be collected. It is the DSA's reference to the next page. If the DUA wishes to retrieve the next page, it must submit another List or Search operation. This time the paged results request parameter is set to Continued Request, and the octet string is returned to the DSA. This allows the DSA to find the next page. The last page of results will not contain a query reference, and so the DUA will know that there are no more pages to retrieve. If the DUA does not wish to retrieve any more pages, it is a local DSA implementation-administration issue as to how long the results are kept before they are discarded.
Table 5.17 The parameters of the Search Argument
| Search Arguments | Described in |
| The purported name of the base object from where the search is to start | 5.6 and 5.10 |
| The portion of DIT to be searched (the scope) | 5.10 |
| The filtering criteria to be applied to entries within the scope | 5.10.1 |
| Flags if aliases within the scope should be dereferenced | 5.10 |
| Entry Information Selection | 5.6.1 |
| *Requesting Paged Results | 5.9 |
| *Additional filtering criteria to be used by '93 DSAs in a mixed environment | 5.10.1 |
| *Flags if only attribute values matching the filter should be returned | 5.10 |
| Common Arguments | 5.4 |
The user provides the purported name of a base object. The Search operation is to start scanning the DIT from this point. This can be any entry in the DIT, including the root, but it is not recommended searching from the root of large DITs unless you have lots of money and time! (Actually this is not true for corporate X.500 Directories, which only hold the names of their employees). Searches only normally proceed from the base object down the DIT towards the leaves, until the user defined scope is completed. The scope takes one of three values:
Each entry within the scope of the search is tested to see if it passes the user defined filtering criteria. If it does, then it will be included in the Search result (assuming that the user has access rights to the entry - see Chapter 8). If it fails to pass through the filter, or the user does not have access rights to the entry, then it will be omitted from the set of results.
Users normally only specify one set of filtering criteria, and these are to be used by all DSAs evaluating the Search operation. However, in a mixed environment of '88 and '93 DSAs, it is possible to specify two sets of filtering parameters. The first filter is to be used by '88 DSAs, and the second is to be used by '93 DSAs. This might be useful when you really want to use a '93 extensible filter, but do not know in which type of DSA the entries are held. A sub-optimal '88 filter is specified first, just in case the entries happen to be held in an '88 DSA (since an '88 DSA is not be capable of evaluating the '93 extensible filter - see § 5.10.1).
Each entry within the Search result will only have the information included that was requested by the user via the entry information selection parameter. This is identical to the way that information is selected for Read results, with one addition. With the Read operation, the user can only request attribute types and no values, or attribute types and all values. With a search, the user can also request attribute types and matched values only. This is signalled via a boolean in the search arguments. Matched values are those attribute values that matched the criteria provided by the user in the filter. Other values in a multi-valued attribute will not be returned; see also w/w 5.8.
The coarsest (search) filter - an and with no filter items - selects all DIT entries within the scope of the Search operation. The finest filter - an or with no filter items - selects no entries from the DIT (quite what use this would be I am not sure!). By carefully constructing your filter it is possible to select just the entries you want from a given portion of the DIT. (That is the theory at least. In practice it may not be quite so easy to specify the right filter for the job, hence some '93 additions to how a filter is specified.)
Industrial filters select on the size of the particles, whilst search filters select on the presence of attribute types and values in entries.
The basic component of a (search) filter, is the Filter Item. This specifies one criteria by which to select entries from those within the scope of the search. The evaluation of a filter item against the attributes in an entry yields a True, False or undefined result. For example, if a user presents a filter with a filter item of age greater or equal to 21, then all DIT entries in the scope of the search, which have age attribute values of 21 or over, will be selected (filter item evaluates to True). Those entries not having an age attribute will not be selected (the filter item evaluation is undefined), and those having age attribute values of 20 or less will not be selected (the filter item evaluates to False).
Filter items may optionally be combined, using the logical operators and, or, and not to form arbitrarily complex filters. Only if the final filter evaluates to True, is the entry selected. So, for example, it would be possible to have a filter of age greater or equal to 21, and sex equal to male and object class equal to person. This would now only select the entries of men aged 21 or over. Entries without either the sex or the age attribute would not be selected. Neither would the entries of women or men aged under 21. Neither would entries that did not have an object class (or super class) of person.
The different filter items available to users are shown in Table 5.18.
The first point to note about all the filter items, is that attributes in the entry can only be tested against them if access controls permit (Chapter 8). Without the necessary access permissions, the filter item will always evaluate to undefined.
Table 5.18 The different filter items
| Filter Item | Selection Criteria |
| Equality | Entry contains an attribute value equal to the presented one |
| Substrings | Entry contains an attribute value matching all the presented substrings |
| GreaterOrEqual | Entry contains an attribute value greater than or equal to the presented one |
| LessOrEqual | Entry contains an attribute value less than or equal to the presented one (w/w 5.5) |
| Present | Entry contains the presented attribute type |
| ApproximateMatch | Entry contains an attribute value approximately equal to the presented one |
| *ExtensibleMatch | '93 defined additional matching criteria |
In general, when an entry contains multiple valued attributes, each is available for testing against the filter item. If just one of the attribute values passes the test, then the filter item evaluates to True.
Each attribute type has a series of matching rules defined for it (§ 3.3). A filter item can only be tested against those attributes which have the corresponding matching rule(s) defined for them. All filter items, with the exception of present, require an equality matching rule to be defined for the attribute type. (The present filter item does not need any matching rules to be defined for the attribute since attribute values are not matched.) In addition, the substrings filter item requires a substrings matching rule, and greater or equal and less or equal filter items need an ordering matching rule to be defined for the attribute type. So for example, an attribute which has equality and ordering matching rules defined for it, cannot support substrings filter items.
Several of the above filter items are worthy of further explanation. The substrings filter item allows the user to present a series of substrings, one of which may be designated as the initial string, one as the final string, and the remainder as strings occurring anywhere in the attribute value. An example of the use of substrings in a Search request is given in § 5.10.4, and further substring matching examples are given in Chapter 3.
The approximate match filter item is not standardised. So the rules governing which attribute values approximately match a presented value are not defined in the Standard. Individual vendors may implement their own national or regional algorithms to perform this task, based for example on phonetics. The soundex algorithm (Knuth, 1973) is a well known algorithm for matching English words through a simple 'sounds like' algorithm, and this has been used to good effect by the Quipu (Robbins and Kille, 1991) implementation.
Complex attribute types may be very awkward to match against (for example the subschema policy operational attributes). It would be much easier for a user to specify a simple component of the attribute type, such as an integer or an object identifier, and ask the Directory to match the attribute value that contains this integer or object identifier embedded in it. (Matching against one component of a complex structure is similar to matching one substring from a large string.) This has been achieved by defining the first component matching rules (w/w 3.9).
Allowing presented values to be different from stored attribute values is allowed by '93 DSAs, but not by '88 ones. This is described more fully in § 3.3.5.
Since '93 DSAs support attribute hierarchies, filter items containing attribute super-types will also be compared against any of their attribute sub-types that are held in the entry. Collective attributes are also available for testing against presented filter items.
ExtensibleMatch also allows additional matching rules to be independently specified and used by various communities of Directory users, as and when a need arises. The filter item is thus infinitely extensible in its meaning and usage. The complete set of parameters that comprise the extensibleMatch filter item are given in Table 5.19.
Table 5.19 The parameters of ExtensibleMatch filter item
| Parameter | ASN.1 Parameter Encoding |
| The matching rule(s) describing how the comparison is to be performed | SET OF Object Identifiers |
| The user presented value to be used in the comparison | An attribute value (typeless) |
| The type of attribute in the entry that is to be used in the comparison | Attribute Type OPTIONAL |
| In addition, use the attributes of the distinguished name in the comparison | BOOLEAN DEFAULT FALSE |
It is possible to define new matching rules as needs dictate. For example, an English variance matching rule might be defined for names, that matches English values with their Italian counterparts e.g. Florence matches Firenze, and Italy matches Italia. Providing that the Italian DSA implementation is enhanced to support this new rule, a user would be able to dynamically select for any given Search operation, whether to use the standard equality rule (and provide Italian names), or to provide English names and use the new English variance rule. This was not possible without extensible matching, since an '88 attribute type could, at most, only have one matching rule defined for each of equality, substrings and ordering.
Note. Whilst '88 implementations may have been able to perform similar matches in other ways e.g. through approximate matching or by holding multi-valued attributes, the '93 extensible matching provides greater flexibility.
Note. that the only attributes in an entry that can be used in the comparison with the user presented value, are those which support the presented matching rule(s).
The user presents an attribute value e.g. integer 3, or string 'MAC', but does not have to specify what type of attribute this is. If attribute type is missing, then typeless matching is performed by the Directory. Every attribute type in the entry, which has a syntax compatible to the presented matching rule, will be used in the comparison. Thus for the value 3, and integerMatch matching rule, the attributes age, number of children, salary, works roll number etc. might be used in the comparison. For the value MAC, and caseIgnoreMatch matching rule, the attributes surname, title, country name, organisation name etc. may be used in the comparison. This considerably enhances the filtering capability of the user.
If the user does specify an attribute type, then only that type and its sub-types may be used in the comparison.
If the user sets the match distinguished name boolean to True, then those attributes in the distinguished name that are compatible with the matching rule will also be used in the comparison.
I am sure that you will agree that extensible matching is a considerable enhancement of the basic '88 filtering capability.
The distinguished name of the base object is only returned if the user provided an alias name in the request. In this situation, '88 DSAs will always return the distinguished name of the entry, but '93 DSAs will only return it if the user has permission to know it (§ 8.6). If the user does not have permission to know the distinguished name of the entry, it will be omitted from the result, just as if the user had provided the distinguished name in the Search request.
Table 5.20 The parameters of the Search Result
| Search Result | ASN.1 Parameter Encoding |
| The distinguished name of the base object | Distinguished Name OPTIONAL |
| The requested information about those entries that passed the filter | SET OF Entry Information (§ 5.6.3) |
| If this is not the complete set of entries then why not | PartialOutcomeQualifier OPTIONAL (§ 5.8.2) |
| Common Results | see § 5.5 |
| Additional uncorrelated Search Results that have been digitally signed by other DSAs | SET OF SearchResult |
The majority of Search operations will be completely processed by the DSA holding the base object, and the Search result will only consist of the above two parameters together with Common Results.
In a few situations this will not be the case. This will be when either the locally generated result is too big, or when one or more of the subordinates of the entry, are located in other (subordinate) DSAs, and the executing DSA is not willing or able to chain the request to them. A partial result is returned to the user, and the partial outcome qualifier describes why the result is not complete (§ 5.8.2).
If subordinates are located in other DSAs, then the executing DSA may chain the request to them. If the subordinate DSAs reply with unsigned answers, then these will be merged with the locally generated set of subordinates to form a complete answer for the user. If however, one (or more) of these subordinate DSAs returns a signed Search result, these cannot be merged with the local result without invalidating their signatures (§ 7.6.2). Consequently, they have to be appended to the local result as a set of uncorrelated Search results. In some situations a subordinate DSA may return an unsigned result which contains an embedded partial outcome qualifier and/or some uncorrelated Search results. Clearly the latter must be copied unchanged into the result generated by this DSA, but the partial outcome qualifier can either be copied into the local result, or acted upon. Acting upon it would cause this DSA to send further chained requests to the DSAs pointed to in the continuation references. You can appreciate that the processing of Search operations can get very complex indeed, and this is before we have even considered replicated entry information! (This is covered in § 9.13.14 and § 9.13.15.)
Finally, the home DSA may offer a paged results service to its DUAs, in which case only a fraction (a page) of this information would initially be returned to the user. The DSA has to store the remainder for subsequent return when the user requests it (§ 5.9).
Fig. 5.4 An example of a Search Request.
We did not ask for the title to be returned, so when we telephone the Directors, we will not know their fields of specialisation.
The Abandon operation only has one parameter, and that is the invoke ID of the operation to be abandoned. The invoke ID is a parameter returned by the remote operations service when an operation is first passed for transfer. It uniquely identifies the operation so that a subsequent result or error, which carries the same ID, can be matched to the operation.
If the Abandon operation succeeds, then two things happen. A null result is returned to the Abandon operation, and an Abandoned error is returned to the original operation. If the Abandon operation fails, then an AbandonFailed error is returned to the Abandon operation, and the original operation continues undisturbed.
Human user interfaces vary tremendously in the facilities offered to users. Some do not make any operation available to the user. They simply extract a purported name from the user and then, via a judicious mix of Search, List and Read operations, present as much information as possible to the user about the requested entry. For example, a DUA developed at Brunel University typically sends out around six operations for each name entered by a user. The user typically enters the name as surname, organisation, country and the DUA does the rest.
Other human interfaces allow users to Read, List or Search areas of the DIT, but do not make parameters such as filters, and entry information selection available to them. The interfaces are typically configured, for Searches, to perform approximate matches on the name components provided by the user, and, for Reads, to read All User Attributes.
The most comprehensive interfaces give the users complete control over their requests, allowing them to set most arguments in all operations. For example, the X-Windows based interface from Nexor [9.2] allows the user to configure the service controls, specify the filters, and select specific attributes from entries.
Table 5.21 The parameters of the AddEntry operation
| AddEntry Arguments | ASN.1 Parameter Encoding | Described in |
| The name of the new entry | (Distinguished) Name | 5.13 |
| The attributes of the new entry | SET OF Attribute | 5.13 |
| *The DSA in which the entry is to be added | AccessPoint OPTIONAL | 5.13.3 |
| Common Arguments | see § 5.4 | 5.13.1 |
The new entry clearly must not exist before the operation is executed. However, the immediate superior of the entry must exist, so that the DIT can only be built up one level at a time.
Any type of Directory entry can be added by this operation - aliases, administrative points, and subentries - but the entries are always added to their master DSAs. In other words, copies cannot be added by this operation, neither can DSEs such as subordinate references (DSEs are not Directory entries).
Note Manufacturers may add local extensions to their administrator interfaces which allow all types of DSE to be created via the AddEntry operation. Also the 96 edition of the standard has created a standard of way of doing this via a new extension flag (Manage DSA).
When adding entries, the set of (user) attributes must be complete. Therefore all those attributes that are prescribed to be mandatory by the local subschema (e.g. content rules and object classes), or system schema (in the case of subentries) must be present. Good user interfaces should give the human user guidance in this area, by prompting him for the expected set of attributes. The Directory (DUA and DSA software) will also add further operational attributes, in order to fulfil additional standardised and local requirements. For example, all entries contain a date-and-time-of-creation attribute (createTimestamp attribute), which is maintained by the DSA software. These attributes are not always visible to the normal user, who will not be aware of their presence.
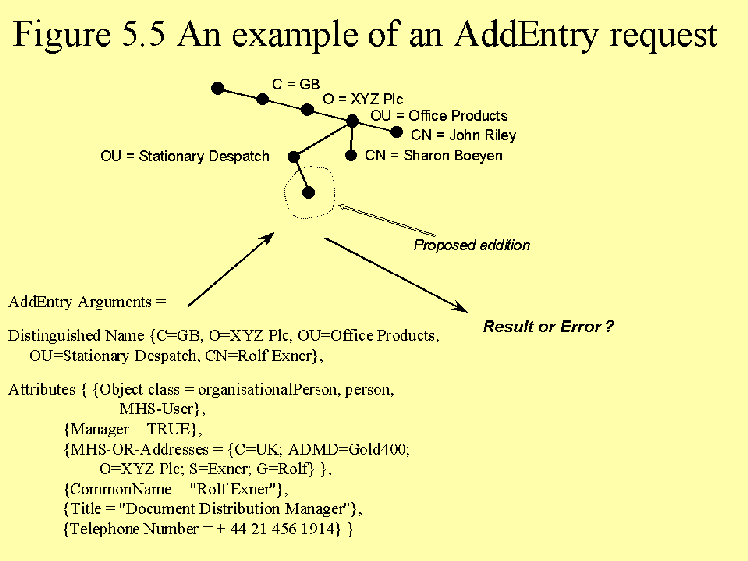
An example of an AddEntry request is given in Fig. 5.5.
Fig. 5.5 An example of a AddEntry request.
One difference between the '88 and '93 Standards is the name presented by the user. '88 DSAs expect the distinguished name of the entry to be added. '93 DSAs are happy to accept alias names and to perform alias dereferencing before adding the entry. The '88 rationale for the restriction was that users should specify the distinguished name of the entry that is to be added, so that the wrong entry is not specified by mistake. '93 systems place much less reliance on distinguished names. Access controls can forbid them being returned, and object identifiers may be used in place of them (see Appendix A).
Note. At the time of writing the draft '93 Standard is unclear as to whether or not Remove Entry mandates a distinguished name. A defect report has been raised to clarify this issue.
Taking checks first, the DSA software needs to check that the user has permission to add the entry and all of the given attributes (§ 8.5.5). Many implementations will not let ordinary users add entries to the DIT, but instead reserve this privilege to Directory administrators. This lock out can be achieved in a number of ways. The most common way is by not providing the DUA software with the AddEntry capability. The next is by specifying, via access control lists or local means, a limited number of users who may add entries. Finally, a higher level of authentication, such as digital signatures, may be required before add privilege is given.
Next the DSA software has to ensure that the new entry (or subentry) conforms to the subschema (or system schema) controlling that part of the DIT where it is to be added. For subentries, this means checking that the immediately superior entry is an administrative point, and that it contains an administrative role attribute with a value that allows the proposed subentry to be added (§ 3.12). The proposed subentry must contain the correct attributes as directed by its object class attribute. Additional local checks may also be imposed, as directed by the implementation.
For entries, the subschema checks are based upon the structural object class of the new entry. The only schema information provided by the user in the AddEntry operation, is a list of the object class(es) of the entry, and its (their) superclasses up to object class Top. There is no ordering implied in the list, and so the DSA software has to determine which superclass chain(s) are implied by the list. In the case of multiple object class membership, there are several superclass chains in the list. Only one of these is the structural chain, the remainder are auxiliary chains (§ 3.7). The '88 Standard did not differentiate between the types of object classes. Consequently, there was no information for the software to determine which of the superclass chains was the structural one. This has been rectified in the '93 edition of the Standard by differentiating between the types of object class, and, by allowing the user to only specify one structural superclass chain when adding an entry. In the example in Figs 5.5 and 5.6, the user provided three values of the object class attribute. The software can work out that these are an auxiliary class (MHS-User), and a structural chain comprising of Organisational Person and Person. (Both MHS-User and Person are subclasses of Top.) The structural object class is therefore Organisational Person.
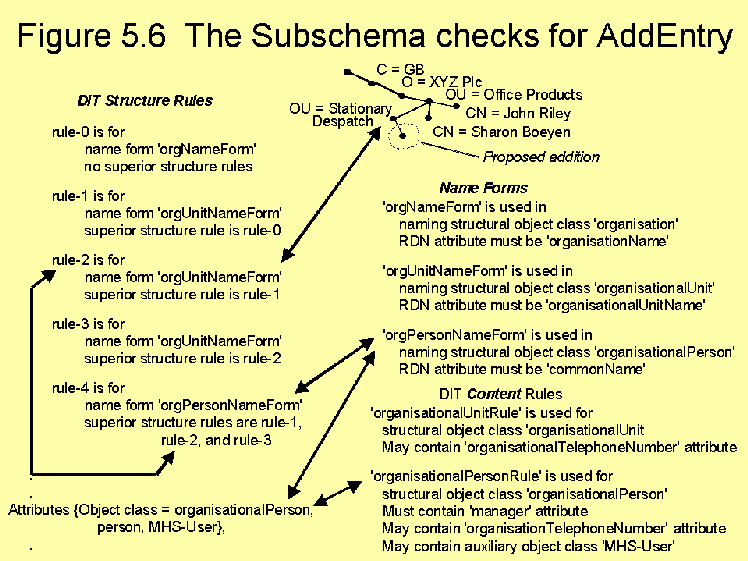
Fig. 5.6 The sub-schema checks for AddEntry.
Once the structural object class of the entry is known (this is the object class at the bottom of the structural chain), the software must check to see if a name form for this object class exists in the subschema. If one does, it must also check if the relative distinguished name of the new entry matches the attributes specified in the name form. This gives the go-ahead to the RDN chosen by the user. In the example, there is a name form for Organisational Person, the orgPersonNameForm. This states that the RDN must be constructed from a Common Name attribute, which Rolf Exner is.
The DSA software then needs to determine if a DIT structure rule for this name form exists. If it does, the DIT structure rule of the immediate superior of the new entry, needs to be contained in the list of possible superior structure rules for the new entry. This gives the go-ahead for the new entry to be placed below its proposed immediate superior in the DIT. In the example, rule-4 is the structure rule for orgPersonNameForm. Its superior rules are rule-1, rule-2 and rule-3. The proposed immediate superior is {C=UK, O=XYZ Plc, OU=Office Products, OU=Stationary Despatch}. The DIT structure rule of this entry is rule-2. Therefore Rolf Exner's entry can be placed below Stationary Despatch.
Next the software needs to check that the contents of the new entry conform to the subschema. This is controlled by both the DIT content rule for the new entry, as well as the definitions of the structural and auxiliary object classes of the entry itself. The DSA software checks if an optional DIT content rule has been defined for the structural object class of the new entry. The DIT content rule (if there is one) and all the object classes and superclasses of the entry (as provided by the user), dictate which user and collective attributes must be mandatorily present in the entry, and which may be optionally present. All other user and collective attributes are not allowed in the entry. Note that the presence of operational attributes in the entry is not controlled by the user. In the example, there is a DIT content rule called organisationalPersonRule that governs the Organisational Person structural object class. This rule mandates a manager attribute in the entry. The MHS-User auxiliary class mandates a MHS-OR-Addresses attribute, and the person structural class mandates common name and surname (Fig. 3.14).
Note. MHS-User object class is defined in the X.400 Standard [5].
The AddEntry operation will thus be rejected, because the user did not provide a surname attribute. (One would not expect this to happen if a good user interface had been used, one which guides the user in which attributes are needed for which object classes.)
Finally, if the DSA has in-built mechanisms for speeding up search operations, such as inverted lists, then pointers to the new entry will need to be added to the appropriate data structures of the implementation. This in itself can involve considerable processing time.
However, the operation is no longer a simple AddEntry operation, but rather is the creation of a HOB between the superior and subordinate DSAs. A significant amount of information needs to be exchanged between the DSAs, in addition to that provided by the user (§ 9.20). For this reason, selection of this option is a designated as a critical extension to the '93 Standard, and some DSAs may choose not to implement it.
{kind=link}
{kind=link}
{kind=link}
{kind=link}