An example of an external application using the Directory to authenticate its users, before allowing them access to the application, would be as follows. Suppose a user wants to initiate a file transfer via FTAM. First of all the user presents his credentials to the FTAM process. Before allowing the user to initiate the file transfer, the FTAM process could:
Additionally, it is assumed that DSAs will store local lists of distinguished name/password pairs, applicable to the DUAs and DSAs that regularly contact them. Since the Standard has not included the UserPassword attribute in the object class of an application entity, it must be assumed that a DSA will only store the password of an external application in its local list, and not inside the application's Directory entry (either that or there is a bug in the Standard). The implication of this is discussed further in § 7.4.1.
Note that the difference between a DSA implementation holding the password of a caller either as an item in a local list, or as the UserPassword attribute of a locally held DIT entry, is indistinguishable in terms of authenticating the caller. (Of course, the difference is noticeable when the complete DIT entry is Read by someone having access rights to it.)
A slightly more complicated procedure can occur when the DSA does not hold the name of the DUA in its local list (or in its local fragment of the DIT). Before responding to the Bind operation, the DSA may initiate a Compare operation, quoting the DUA's name as the purported name, and the password as the purported UserPassword attribute. The Compare operation will then travel around the Directory until it finds the DSA holding the purported entry in its fragment of the DIT (Fig. 7.1). This DSA will return a True or False result to the Compare operation, depending upon the correctness of the purported attribute. When the original DSA receives the result, it can respond appropriately to the Bind operation. Note that this procedure can only be executed if the Bind originated from a DUA, and not from a remote DSA. (Otherwise the Compare operation would not be capable of being sent, since the Compare relies on a Bind having already been successfully established with a remote DSA!) Furthermore, the procedure is only really appropriate for authenticating people, and not external applications. If the DUA was acting on behalf of an external application, it is likely that the Compare result will always be False, as the Standard does not define the UserPassword attribute as being present in application entity entries (although it could be added by local extension to the sub-schema).
Fig. 7.1 Simple authentication, using the Compare operation.
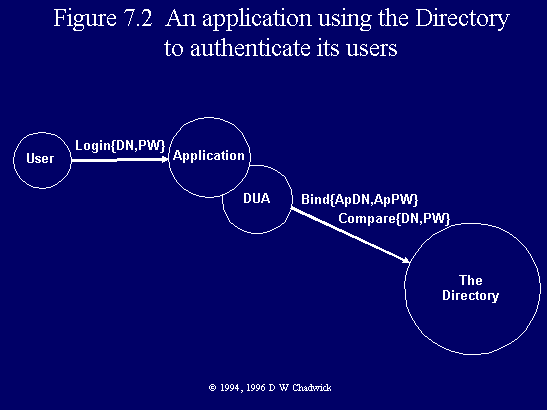
A variance of the above procedure can be used by external applications to authenticate their own users, providing that the Directory stores the distinguished names and UserPassword attributes of these users. First of all, the user logs on to the external application, and quotes his distinguished name (DN) and password (PW). The application (via its built-in DUA) Binds to the Directory and is successfully authenticated by the latter (by any method). Then the application invokes a Compare operation quoting the purported name and password of its own user (Fig. 7.2). If True is returned by the Directory, the application will accept the user, and if False, it will reject him. The rationale behind this procedure is that the Directory can act as the central repository for all usernames and passwords, and that all (OSI) applications can use the Directory to authenticate their own users. This seems sensible, given that users of the Directory will already have the information stored in the Directory (providing that the Directory uses passwords for its user authentication).
Fig. 7.2 An application using the Directory to authenticate its users.
The main weakness in all of the above schemes is that passwords are transmitted in the clear across the network. This is obviously a security loophole, and will make it easier for one user to intercept the password of another. This can be achieved in at least three ways. Transmissions can be passively monitored, and the passwords extracted from the messages. Alternatively, if a user is not sure who the remote entity is, and it turns out to be a 'bad guy', then he has revealed his password to this entity through having to send it in the Bind operation. This situation can occur in the Directory when a user receives a referral to a remote DSA. The user may never have contacted that DSA before. (It may not in fact be a DSA.) There is thus a risk involved in sending your password on the Bind operation to an unknown destination. Finally, in connectionless networks, such as the Internet, the route that your Bind message takes is not known before you send it. It could go via an insecure node, that copies your password, or it could be inadvertently routed to the wrong destination. Either way, your password could fall into the wrong hands. Once your password has been intercepted, the interceptor is in a position to masquerade as you.
For these reasons, a more secure procedure is defined, which is based on protected passwords. Protected passwords use a one-way function to encode them prior to transmission. Whilst this does give some protection, it is not a complete solution as we shall see later. Protected passwords work as follows.
Protected passwords as described above, offer only limited protection against masquerade, and they do not protect against replay. Replay is the security attack, whereby an offender re-transmits a valid message (or part of it) at a later point in time. By re-transmitting your protected password and the algorithm's associated parameters, the offender may still be able to masquerade as you. The attacker may thus be able to gain valuable information that was originally transmitted to the rightful recipient, or may be able to cause an action to occur for a second (illegal) time.
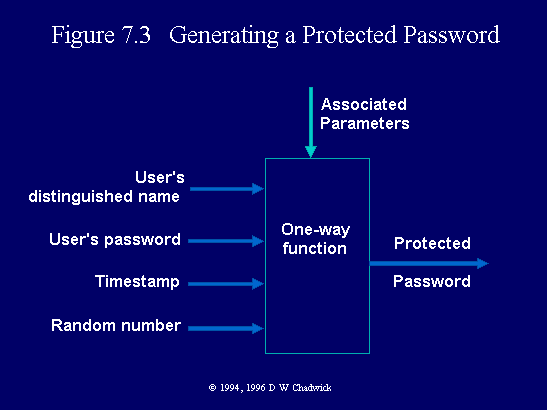
In order to prevent replay and masquerade, a slightly more complex protected password procedure is employed. With this procedure, the distinguished name, the password, and a timestamp or a random number or both, are first passed through the one-way function (Fig. 7.3). This more complex protected password is then passed in the Bind operation, along with the distinguished name, the identifier of the one-way function and its associated parameters, and the same timestamp or random number or both, all of which are in the clear (Table 5.1). The receiving DSA can then regenerate the protected password, from the password in its local list and from the distinguished name, timestamp and/or random number, and the one-way function's associated parameters, obtained from the Bind operation. If the protected passwords are the same, the Bind can be accepted, if they are different, the Bind will be rejected. A subsequent replay of a previously valid Bind, will be rejected because either the timestamp has expired, or the random number is the same as a previous one. (The latter obviously requires the DSA to remember previous random numbers. This is simplified when a timestamp is used in conjunction with random numbers, since the latter only need to be remembered for the duration of the timestamp.) Note that both parties to the communication must be able to recognise the object identifier of the one-way function and to know how the clear information is to be used in generating the protected password.
The protected password procedure as described above has one limitation, and that is that the clear password must be held by the receiving DSA (either in a local list or in a Directory entry). The Compare operation cannot be used to pass the protected password to another DSA. A recent defect report would have enabled protected passwords to be passed between DSAs, via the Compare operation (w/w 7.8). Unfortunately the defect was rejected due to the objections of some experts.
Protected passwords still do not give complete protection. In the case where your Bind operation was sent to a 'bad guy' by mistake, or was routed to a wrong node in the network, the interceptor is in possession of a valid authentication token. The interceptor can use your protected password once, before it becomes invalid. For this reason, it is not recommend to use passwords or protected passwords, when either you cannot trust the network, or you do not know the remote entity that you are Binding to.
Fig. 7.3 Generating a protected password.
Finally, the ultimate procedure in protected passwords may be used, which offers a double dose of encoding. By taking the encoded output from applying the one-way function as described above, and combining this with another timestamp and/or random number, and applying a second one-way function to them, a doubly protected password is produced. This is sent in the Bind operation to the receiving DSA, along with the two timestamps and/or random numbers, an identifier of the two one-way functions (plus the associated parameters of both), and the distinguished name of the sender (Table 5.1). Clearly both parties have to have prior knowledge if this authentication procedure is being used. Double encoding should make it computationally infeasible to determine which password produces which protected password.
A few words of caution need to be raised. It is unlikely that a DSA will want to distribute its password (or even its protected password) to any of its local users, and so mutual simple authentication involving a DUA is unlikely to take place. (However, the Standard does not forbid it from happening.) Secondly, it is unlikely that a DSA will want to send its password or its protected password to an unknown DSA, for the reasons outlined above. Therefore administrator to administrator negotiations will need to take place before a DSA will be willing to enter into mutual simple authentication with a new remote DSA. (The current pilots do not have this problem as the DSA to DSA Binds are currently unauthenticated.) Finally, if both DSAs know each other, but do not trust the network, it still will be unlikely for them to reveal their passwords to the network. Therefore a better means of authentication is needed, one that can work reliably over an untrustworthy network.
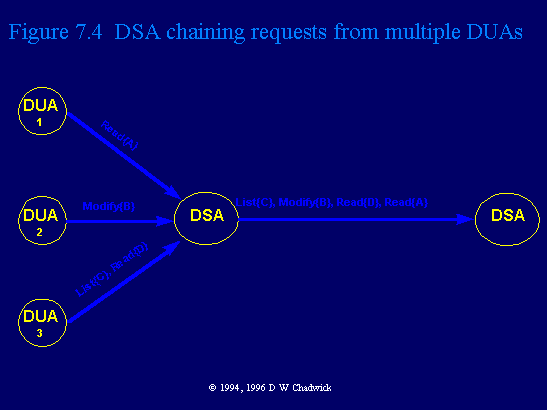
There is one fundamental difference between the DAP and the DSP. Each operation that is passed down the DAP must come from the same user. There is no need for the user to provide any authentication information on each of his requests, since the home DSA authenticated him at Bind time. Therefore each operation is implicitly authenticated as coming from the same user. However, each operation that is passed between DSAs in the DSP could have originated from different users (Fig. 7.4). Authentication at DSA Bind time will not determine who is the ultimate originator (DUA) of each operation. This information is not known at DSA Bind time, and so it must be carried later in each chained operation. The DSA Bind only serves to authenticate each DSA to the other.
Fig. 7.4 DSA chaining requests from multiple DUAs.
The simplest solution is for the home DSA to insert the name of the
originating DUA into the Chaining Arguments of every request that it chains
onwards. This was adopted by the '88 version of the Standard. Another solution
is for the home DSA to insert the name of the originating DUA plus an indication
of the level of authentication that it carried out (i.e. whether no password,
a clear password, or a protected password was used etc.) This has been
adopted by the '93 version of the Standard (w/w 7.1). A further solution
would be to pass the complete credentials of the user (i.e. name and password)
between DSAs.
(No one has seriously suggested adopting this solution,
since this would mean that the final DSA has to authenticate the user again.
In nearly every case this would cause a Compare operation to be spawned
by the final DSA, before the original operation could be performed. Furthermore,
the final DSA would have to trust the presented password and the returned
Compare result, so it might as well trust the initial DSA to authenticate
the user.)
However, each solution has the same drawback, and that is, that each DSA must trust the preceding and succeeding DSA not to manipulate this information in any way. Without this trust a DSA cannot even rely on a chained name and password. Ideally, an authentication mechanism is needed that can work reliably in a distributed environment, without the need for any Directory component to trust any other component. This is the basis of strong authentication. Without strong authentication, DSAs will have to keep lists of trusted DSAs, and check each incoming chained request. The trace information (§ 9.13.5) of each received chained request may be scanned to check that only trusted DSAs have handled the request. If so, then the authentication information may be trusted. If not, the request will have to be assumed to be unauthenticated, since the authentication information cannot be trusted.
There is another type of encryption algorithm - the asymmetric encryption family of algorithms - that has the strange property that one key is used for enciphering the data, and a different key is used for deciphering the data. The two keys come as a pair, and are mathematically related via the encryption algorithm. Now if a user makes one of the keys, say the encrypting key, publicly available, and retains private ownership of the deciphering key, then that user has the basis for confidentiality (providing that the deciphering key cannot be derived from the encrypting key). Anyone can encipher a message with the public key, but only the user is able to decipher it. Conversely, if a user makes the decrypting key publicly available, and retains private ownership of the enciphering key, then that user has the basis for authentication (providing that the enciphering key cannot be derived from the deciphering key). The user can encipher a message with his private key, which any recipient with the public key can decipher. The receiver knows that the message must have come from the user, as the user is the only person with the complementary key of the pair, and this key is the only one which was capable of performing the initial encipherment. This is the basis of digital signatures, used for strong authentication by the Directory.
The Directory Authentication Framework mandates the use of permutable asymmetric encryption algorithms, although in the future this requirement could be relaxed (although no such work has yet been started).
One of the disadvantages of the known permutable asymmetric encryption algorithms is that they are very processor intensive. Consequently, they can only sensibly be used with small messages - since most people do not have access to the supercomputers which would be needed to encipher or decipher large messages in a short time. The Standard therefore recommends that messages are first reduced to a small size (64 bytes is suggested for the RSA algorithm) by a hashing algorithm, before encryption with the private key.
The process of hashing the data, followed by encryption of the hash value with the private key of the sender, is known as signing the data (Fig. 7.5). The encrypted hash is known as a digital signature. The sender transmits both the message (in the clear) and the digital signature to the receiver. Together these are known as digitally signed data, or signed data.
Fig. 7.5 Strong authentication of a sender.
Digital signatures are to electronic data what human signatures are to written data. A signature on a cheque is the method of guaranteeing its authenticity (although due to their ease of forgery an additional credential is now usually needed such as a cheque guarantee card). Alterations to the contents of the cheque require an additional authenticator, usually the initials of the signatory. Similarly, digital signatures guarantee the authenticity of the electronic data, and if the data is altered, a new digital signature is needed.
When the receiver receives a digitally signed message, the first step is to separate the signature from the clear data. The data is passed through the same hashing algorithm as that used by the sender, in order to compute the hash value. The digital signature is deciphered, using the public key of the sender, in order to obtain the hash value computed by the sender. The two hash values are compared, and if identical, the message is assumed to be authentic. It must have come from the sender, and it cannot have been altered on route, otherwise the two hash values would be different. The receiver therefore does not need to trust any intermediate process that handled the message, since it is using authentication information provided by the sender.
Note that the sender transmits both the message in the clear, as well as the digital signature. Remember that this is the authentication framework, and not the confidentiality framework, and so it is quite acceptable that the message is sent in the clear. The aim is that the receiver can be sure of who the originator is, without having to trust the Directory to tell him. It just so happens that digital signatures have been designed in such a way that, as well as authentication, message integrity is also provided. No mechanism is currently provided by the Directory for message confidentiality.
In summary then, digital signatures have the following properties:
The abstract value of an operation argument or result, is unambiguous in its meaning. However, the conversion of this into the standard transfer syntax, using the BER, is not completely definitive. For example, the Boolean True, after application of the BER is defined to be not equal to zero (but will the transfer octet be 01 or 99?), and for a SET construct, the elements can be encoded in any order. Therefore two different implementations may produce, from the same value of an abstract data type, different sequences of octets for transfer to another site. Hashing two different sequences of octets will obviously produce two different hash values.
Thus the same abstract data could produce different hash values at the receiving and sending sites, and so the signature would be declared invalid when it is not. In order to avoid this possibility, the '88 Standard defines a set of distinguished encoding rules for the BER, that guarantee definitive values in the transfer syntax for all operation arguments and results. The distinguished encoding rules effectively eliminate any options allowed by the BER. This work has spawned an extension [4.4] to the ASN.1 standard, which is due to be completed in 1994 (w/w 7.5).
for completeness sake, as this is used for protecting passwords as mentioned in §5.2.) An example of the use of the SIGNED MACRO, to an (undefined) type OperationResult, is given in Fig. 7.6b. As can be seen, the SIGNED MACRO allows the standard's writers a shorthand way of defining a particular data type to be a signed data type (although the notation does not necessarily aid understanding!). The '93 Standard has replaced the macros by four equivalent ASN.1 Information Objects, the hashed, encrypted, signed and signature objects. These are shown in Fig. 7.6d.
The ENCRYPTED MACRO, and its associated text, is a shorthand way of saying that the (abstract) values of any ENCRYPTED data type (DataTypeToBeEnciphered), are always bit strings (VALUE BIT STRING). A bit string is produced by firstly applying the ASN.1 Basic Encoding Rules to a value of the original data type, to produce transfer octets, and then enciphering these using an encryption algorithm.
The SIGNED MACRO is a short hand way of saying that by defining a data type (DataTypeToBeSigned) to be a SIGNED data type, (abstract) values of the SIGNED type (as specified in the VALUE NOTATION), will comprise a sequence (VALUE SEQUENCE) of:
SIGNED MACRO ::=
BEGIN
TYPE NOTATION ::= type (DataTypeToBeSigned)
VALUE NOTATION ::= value (VALUE SEQUENCE {
DataTypeToBeSigned,
AlgorithmIdentifier,
- of the algorithms used to compute the signature
ENCRYPTED OCTET STRING } )
- where the octet string is the result of the hashing of the
- value of 'DataTypeToBeSigned'
END
AlgorithmIdentifier ::= SEQUENCE {
algorithm OBJECT IDENTIFIER,
associated parameters ANY DEFINED BY algorithm OPTIONAL}
SIGNATURE MACRO ::=
BEGIN
TYPE NOTATION ::= type (DataTypeOfSignature)
VALUE NOTATION ::= value (VALUE SEQUENCE {
AlgorithmIdentifier,
- of the algorithms used to compute the signature
ENCRYPTED OCTET STRING } )
- where the octet string is a function (e.g. a compressed or hashed
version)
- of the value of the 'DataTypeOfSignature'
END
The SIGNATURE MACRO is very similar to the SIGNED MACRO, and says that abstract values of a SIGNATURE data type (DataTypeOfSignature) consist of an encrypted data value and an algorithm identifier, but do not contain the data value itself. Thus when applied to passwords, the SIGNATURE of a password carries the protected password (as an ENCRYPTED OCTET STRING), plus the algorithm identifier of the one-way function(s) that performed the encryption, but does not carry the password in the clear. A SIGNED password, on the other hand, would carry the password in the clear, as well as an encrypted version of the password.
It is important to note that the transformations that are actually performed on the data values, by application of either of the SIGNATURE or SIGNED MACROs, are the ones that are defined by the algorithms that will operate on the data values. The macros are really just a shorthand way of saying that an encrypted value is present, together with the object identifier of the encrypting algorithms, plus any associated parameters that the algorithms require.
SignedResult ::= SIGNED OperationResult
SignedOrUnsignedResult ::= CHOICE {
OperationResult,
SIGNED OperationResult }
The '88 Standard also defines an OPTIONALLY-SIGNED MACRO, which is defined as a choice between the data type as it is, or the signed version of the data type i.e. it is equivalent to the CHOICE in Fig. 7.6b. By reference to Figs 7.6b and 7.6c, one can see that the OPTIONALLY-SIGNED MACRO is a shorthand way of expressing this choice, since the right hand assignments to SignedOrUnsignedResult are equivalent in Figs 7.6b and 7.6c. The Standard uses the OPTIONALLY-SIGNED MACRO throughout Part 3 to signify when operation arguments and results may optionally be signed. In fact, by reference to Chapter 5, the Standard says that all operation arguments, for example the Read arguments (§ 5.6), may be optionally signed, and that all operation results, except the modification results (which are null), may be optionally signed. The errors (§ 5.18) may not be signed.
The '93 Standard has replaced the macro notation by the Information Object Class notation. The HASHED Information Object Class, introduced in the '93 Standard, says that a value of a hashed data type (DataTypeToBeHashed) is always an OCTET STRING; and that the octet string is constrained to be that which is created by first converting the data value into its transfer syntax (which is a series of octets) using the ASN.1 Distinguished Encoding Rules, and then hashing this series.
ENCRYPTED { DataTypeToBeEnciphered } ::= BIT STRING (
CONSTRAINED BY {
- must be the result of applying an encipherment
- procedure to the BER-encoded octets of a value of
DataTypeToBeEnciphered } )
SIGNED { DataTypeToBeSigned } ::= SEQUENCE {
DataTypeToBeSigned,
COMPONENTS OF SIGNATURE { DataTypeToBeSigned }}
SIGNATURE { DataTypeOfSignature } ::= SEQUENCE {
AlgorithmIdentifier,
ENCRYPTED { HASHED { DataTypeOfSignature } }
- Encoding rules are only applied once
}
SignedOrUnsignedResult ::= CHOICE {
OperationResult,
SIGNED { OperationResult } }
The ENCRYPTED Information Object Class is the '88 ENCRYPTED MACRO re-written using the new ASN.1 notation. It has identical semantics. The same is true for the SIGNATURE Information Object Class, but in addition, OCTET STRING has been replaced by the HASHED data type that generated it. The SIGNED Information Object Class is also a translation of its macro counter-part, but it has also had an additional change made to it. It now identifies that a SIGNED data value comprises of a signature (COMPONENTS OF SIGNATURE) as well as the plain data value (DataTypeToBeSigned).
The application of '93 information object classes is very similar to the application of '88 macros, the only difference being in the addition of curly brackets { } which aids machine parsing, and an example is given in Fig. 7.6e.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}