The root of the DIT causes problems from a managerial and operational perspective. The Standard has stated that First Level DSAs should co-operate to manage the root of the DIT, but no guidelines are given as to how this might be achieved. Several sections, 9.7 to 9.9, look at what First Level DSAs are, what information they are obliged to hold, how they might function, and how administrators might co-operate to share knowledge about the root of the DIT. This discussion is then extended to the management of a country's entry and an organisation's naming context.
The modes of interaction between DSAs, termed chaining and referrals, were introduced in Chapter 4. The '93 Standard has introduced some new terminology in this area, and removed some old terminology i.e. multicasting. This will be explained fully in § 9.10 to § 9.12. How the DSAs co-operate to answer a user's query, by adding 'state' information to the request, was also introduced. The parameters that make up this 'state' information - the Chaining Arguments - are fully described in § 9.13.
The '93 Standard has introduced the new concept of Operational Bindings, as explained in Chapter 4. In § 9.15 to § 9.18 of this chapter, the generic parameters that make up the Directory Operational Binding Management Protocol are described, and in § 9.19 and § 9.22 the specific parameters of the Hierarchical Operational Binding are explained.
The '93 Standard added to these: immediate superior reference, supplier reference, consumer reference and master reference. The latter three arose from the work on replication (shadowing).
Each knowledge reference only points to one DSA (w/w 9.1). It can be seen that once subtrees/naming contexts are replicated, there may be several remote DSAs that hold copies of the same subtree. There could therefore be several Access Points/knowledge references associated with the same DIT name. However, one of these Access Points (or knowledge references) will be in a different category to the rest. This is the knowledge reference that points to the DSA holding the master copy of the naming context, and it is called the master reference. Shadow references, on the other hand, are knowledge references that point to DSAs holding shadow copies of (possibly part of) a naming context.
Within the DSA Information Model, both categories of knowledge reference are actually stored together in one complex attribute type e.g. the specific knowledge DSA shared operational attribute - see § 9.4. Within a particular knowledge attribute value, each Access Point has a flag to indicate whether it is the master or a shadow reference. In this way the DSA knows which knowledge reference is to the master copy of the naming context, and which are to shadow copies of the naming context.
Within the Directory protocols, both categories of Access Point are carried together in one construct (Access Point Information - see § 9.3). Again, these Access Points are flagged as being master or shadow Access Points. Therefore the DSA receiving this information is able to tell which access point points to the master DSA, and which point to shadow DSAs.
When configuring a superior reference into a DSA, an administrator might, subject to bilateral agreement, use one of its immediately superior references.
A DSA holding several subordinate references therefore knows which subordinates of an entry are held in which remote DSAs (assuming that an entry has two or more subordinates held in different remote DSAs). It also knows which subordinates do not exist, since it either holds all the subordinate entries itself, or it has subordinate references to the ones that it does not hold.
For a non-specific subordinate reference, the Access Point is to a DSA which holds a copy of one or more subordinate naming contexts, and the name (RDN) of the DIT entry that is being pointed to, is unknown. You can think of the RDN being a wildcard, or 'any', i.e. the referenced DSA holds subordinates that may have any RDN.
Immediate superior references are needed for hierarchical Operational Binding management. They are also useful during distributed name resolution.
Cross references enable the process of distributed name resolution to proceed far more quickly and efficiently than when they are absent. They allow a DSA to bypass the normal mechanism of distributed name resolution (§ 9.6), since the DSA can pass the operation directly across the DIT to a DSA nearer to the entry. Cross references point arbitrarily across the DIT, and usually will be held by DSAs that frequently access remote portions of the DIT.
A supplier reference may be used by a DSA during name resolution, when the operation needs to be directed to the master copy of an entry, for example, if the operation is a modify operation or the user has set the 'do not use copy' service control. A supplier reference is held as part of the supplier knowledge attribute in the context prefix of the naming context which is being (possibly partially) shadowed.
Consumer references are held in the consumer knowledge attribute. Consumer references are never used during name resolution, but are used for propagating updates to shadows.
One reason for the extension of access points, is due to the choice of lower layer protocols that a remote DSA may support. Each Access Point may now optionally carry, in a Protocol Information parameter (Fig. 9.1), the protocols and profiles that are supported by the underlying transport and network layers of the remote DSA's presentation address. This allows a calling DSA to use the received access point information efficiently, without having to test, by trial and error, many different lower level protocol combinations. Of course, '88 DSAs will always ignore this parameter, due to the rules of extensibility (§ 5.19).
With the introduction of replication, each Access Point is now categorised as being either a master or shadow access point (Fig. 9.1). If the categorisation flag is missing, master is assumed (i.e. master is the default). Thus '88 DSAs are always assumed to pass in protocol the access points of master copies of naming contexts (since they will never append the categorisation flag). Only '93 DSAs may flag access points as being to shadow copies of naming contexts, and '88 DSAs will always ignore this flag, due to the rules of extensibility (§ 5.19).
Furthermore, access point information now consists of one specially selected access point, followed by a set of optional additional access points. The logic behind this is as follows. An '88 DSA will always generate, and expect to receive in the Directory protocols, just one access point, since this was all that was defined in the '88 Standard. A '93 DSA will treat an '88 generated access point as the specially selected access point. A '93 DSA, about to generate access point information, may have available to it a set of access points, which all reference different DSAs holding copies of the same naming context (due to replication). When generating the access point information it will choose the best access point from the set, sending this as the first component of access point information, and the remainder as the second component - see Fig. 9.1. (It might be sensible for '93 DSAs to always choose the master access point as the specially selected one.) An '88 DSA receiving access point information from a '93 DSA, will only use the specially selected access point. It will ignore all the additional access points, as it does not expect nor understand them. A '93 DSA receiving access point information may choose the specially selected access point, or may choose any access point from the additional set. Only one access point from access point information is initially chosen, since all the DSAs point to copies of the same naming context. If the DSA pointed at in the chosen access point cannot reply, for example, it is down, or it responds with a soft error (§ 9.12), then the '93 DSA is free to choose another access point from access point information.
One additional complication arises (as always) from NSSRs. In the '88 Standard the only time that a DSA would forward a set of access points to another DSA, would be when it encountered a set of NSSRs at an entry during name resolution. Each of these access points needs to be followed by
Fig. 9.1 Access Point Information.
the receiver, in order to contact all of the subordinates of the entry. In the '93 Standard, it is recognised that each DSA pointed to by a NSSR may have replicated its naming context(s), and therefore we may now have a set of access points arising from each NSSR. We thus may have a set of sets of access points! At least one DSA from each set of access points needs to be contacted, in order to contact the complete set of subordinate entries. Thus, in the case where NSSRs have been encountered, the set of access points is now replaced by a set of access point information (§ 9.11).
Knowledge references are modelled as being held in DSA specific and DSA shared operational attributes. If the contents of a knowledge reference are specific to a single DSA, then they are held in a DSA specific operational attribute. If the contents of a knowledge reference may be shared by all the DSAs that hold it, then it is held as a DSA shared operational attribute. An example of the former would be the superior knowledge attribute, used for holding the superior reference. Whilst all non First Level DSAs hold a superior reference, most of them will point to different DSAs. The value is therefore not shared by all DSAs. An example of the latter is the specific knowledge attribute, used for holding subordinate and cross references. This points to all the DSAs that hold copies of a naming context. Clearly these values will be the same whichever DSA holds them. (Whilst some DSAs will hold this attribute as a subordinate reference, and others as a cross reference, this difference is flagged via the DSE type bit - see Table 2.1. The values of the attribute do not change. (In reality, because of security or other operational reasons, the access point values held by some DSAs may be different i.e. not all DSAs may know about the complete set of DSAs holding (possibly partial) copies of a particular naming context. All DSAs will hold a subset of the complete set of access points.) Table 9.1 lists the different types of knowledge attribute that have been defined, along with the knowledge references that they can be used to represent. The only thing left to determine, is in which DSEs they are held.
The obvious place in the DSA Information Tree to hold a knowledge reference attribute type, is in the DSE which equates to the name of the DIT entry that the knowledge reference points to. Thus a superior reference is held in the root DSE, since it logically points to the root of the DIT. Subordinate references are held in the appropriately named DSEs, that are subordinate to the entry at the edge of the naming context. Supplier, master and consumer references are held in the context prefix entry of the naming context that has been replicated. Immediate superior and cross references are held in the DSE which equates to the last RDN of the context prefix of the remote naming context. That just leaves NSSRs! Since the names of the entries that they point to are not known, in which DSE can they be held? One option was to create a DSE, with the name being a wildcard, that was subordinate to the entry at the border of the naming context, and to place the knowledge attribute in this. However, the solution that was finally agreed upon was to place the non-specific knowledge attribute actually in the entry at the border of the naming context.
Table 9.1 The knowledge operational attribute types
| Knowledge Attribute Type | DSA Shared/Specific | Knowledge Reference |
| My Access Point | DSA Specific | Self |
| Superior Knowledge | DSA Specific | Superior |
| Specific Knowledge | DSA Shared | Cross
Subordinate Immediate Superior |
| Non-specific Knowledge | DSA Shared | NSSR |
| Supplier Knowledge | DSA Specific | Master
Supplier |
| Consumer Knowledge | DSA Specific | Consumer |
| Secondary Shadow Knowledge | DSA Specific | see § 9.5 |
Fig. 9.2 Knowledge references in a DSA Information Tree.
Suppose XYZ Inc has a distributed Directory system. The corporate headquarters (distinguished name {C=US, L=Florida, O=XYZ Inc}) and each organisational unit have their own DSA. Fig. 9.2 shows (part of) the DSA Information Tree for the Marketing unit (distinguished name {C=US, L=Florida, O=XYZ Inc, OU=Marketing}) which is held in its non First Level DSA. The DSA Information Tree shows where many of the knowledge references are placed. The superior reference and self reference are held in the root entry. The immediate superior reference, held in the {C=US, L=Florida, O=XYZ Inc} DSE, points to the naming context held at the corporate headquarters. Each organisational unit subordinate to the Marketing unit also has its own DSA. The Marketing unit only knows the RDN of one of these units, and that is the Keys division. Consequently, the DSE {C=US, L=Florida, O=XYZ Inc, OU=Marketing, OU=Keys} holds the subordinate reference to the OU=Keys subordinate naming context. All the other subordinate naming contexts must be referenced by NSSRs held in the DSE superior to them all i.e. {C=US, L=Florida, O=XYZ Inc, OU=Marketing}. The Marketing DSA has shadowed the naming context of the Sales unit i.e. {C=US, L=Florida, O=XYZ Inc, OU=Sales} from their DSA, and it holds a supplier reference to this. The Marketing DSA also has a cross reference to its sister organisation XYZ Inc in Texas i.e. {C=US, L=Texas, O=XYZ Inc}, since it is often in contact with this organisation.
Superior knowledge only holds one access point, so this has to be the specially selected access point of access point information - but see w/w 9.3. Supplier knowledge holds one or two access points, depending upon whether or not the master is the supplier. The DSA will have to choose which one to use as the specially selected access point, but in most cases the master access point should be the preferred choice.
The most interesting mapping is performed by the DSA holding the master copy of a naming context. It is responsible for creating the specific knowledge attribute for a naming context, and for passing this, via Hierarchical Operational Bindings, to the DSAs holding the subordinate and immediately superior naming contexts. The information is drawn from three other knowledge attributes: my access point, consumer knowledge and secondary shadows. Consumer knowledge holds the access points of the DSAs that are receiving the shadow copies directly from this (the master) DSA. Secondary shadows holds the set of consumers who are receiving copies indirectly from this (the master) DSA. (The secondary shadows attribute is actually multi-valued, with each value holding the name of one supplier DSA, and the set of consumers that it is servicing. The set of secondary shadows is provided to the master DSA by its direct consumers, via the Shadowing Operational Binding - see § 6.4.2.) From these two attributes the master DSA is able to construct a list of all the shadow access points that have commonly usable copies of the naming context. Finally the master DSA uses its own 'my access point' attribute to create the master access point in the set of Master And Shadow Access Points. This construct is then stored in the specific knowledge attribute of the context prefix entry, and is carried to the subordinate and immediately superior DSAs via the Hierarchical Operational Binding.
Once a DSA knows the names and addresses of (i) a DSA which is nearer to root of the DIT than it is, and (ii) all of the DSAs which hold all of the subordinates of the entries in the naming contexts it holds, then it is possible for it to indirectly locate every entry in the DIT (providing of course, that all other DSAs hold this minimum amount of information). The Standard mandates that all DSAs should hold this minimum amount of knowledge information. Of course, a special situation exists when we approach the root of the DIT, since the root entry is known not to exist. The Standard has this situation covered via the concept of First Level DSAs, and these will be described more fully in § 9.7.
Appendix B describes how distributed name resolution is performed in a DSA based on naming contexts. It is a slightly simpler version than that described in the '88 edition of the Standard. The appendix takes no account of alias entries. Interested readers should consult the '88 Standard for the full description.
The '93 edition of the Standard uses a different documentation technique for describing distributed name resolution, which is based on DSEs. With this technique, each DSA is modelled as holding a subtree of the DIT, which always starts at the root. Some of the DSEs in this DSA Information Tree may in fact be empty (apart from holding the DSE type attribute) meaning that only their name is known, and these are called glue DSEs. Never-the-less, a fully interconnected subtree of the DIT is held, and within this will be the naming contexts that the DSA masters. Copies of (parts of) other naming contexts, that the DSA has shadowed, will also be held in this same tree.
Distributed name resolution is now the simple process of matching a purported name against the DSEs in the DSA Information Tree, starting at the root. If the purported name matches a DSE exactly, then the name has been resolved. If the entry is held here, then the DSA evaluates the operation. If the DSE is empty (i.e. a glue DSE), then the DSE above this one that most nearly matches the purported name, and which contains a knowledge reference, is used in order to chain or refer the request to that remote DSA (providing of course, that distributed name resolution is being progressed further than that already performed by the preceding DSA). The same is true if an exact match is not found. If distributed name resolution cannot be progressed further by this DSA, then an error is returned to the caller.
By reference to Fig. 9.2, it can be seen how this DSA can perform distributed name resolution for the following purported names:
Actual entries immediately subordinate to the root, are called First Level entries. Country and multinational organisation entries are of this type. Naming contexts with First Level entries at their root, are termed First Level naming contexts. DSAs which hold First Level naming contexts are termed First Level DSAs. First Level DSAs are defined in the Standard, but First Level entries and First Level naming contexts are not. However, for clarity, when referring to entries immediately subordinate to the root, it is convenient to use the term First Level entries. The Standard places extra responsibilities on First Level DSAs as follows.
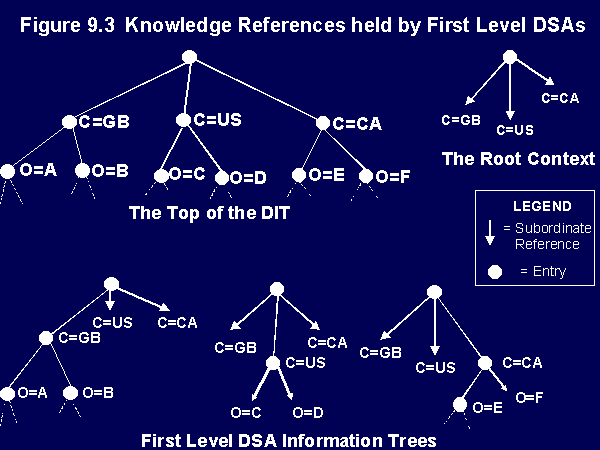
If the root entry did exist as a naming context in a DSA, then this root naming context would consist of a single entry, the root of the DIT, plus a set of subordinate and non-specific subordinate references to all First Level entries in the world. Since the root entry does not actually exist, its contents are empty. Therefore the root naming context - abbreviated simply to root context in parts of the Standard - consists of the name (only) of the root entry, plus the complete set of subordinate and non-specific subordinate references of the root. The Standard mandates that, in order to be a conformant First Level DSA, a DSA must hold a copy of the root (naming) context i.e. have a complete set of subordinate (and non-specific subordinate) knowledge references to all First Level entries in the world that it does not hold. In this way, each First Level DSA is able to perform the function, in distributed name resolution, that the root DSA would have performed, had it existed. Fig. 9.3 shows an example of the knowledge references held by three First Level DSAs, when the root context comprises of just three subordinate references. In the example, one First Level DSA holds only the First Level entry (C=US); another First Level DSA holds the First Level entry (C=CA) and one of its subordinate organisational entries (O=E); and the third First Level DSA holds the First Level entry (C=GB) and all of the organisational entries subordinate to this.
The '88 Standard assumed that there would be one First Level DSA for each country entry, since replication was not supported. In comparison, the '93 Standard expects that there will be many First Level DSAs for each country entry. One of these will be the master DSA, the rest will hold shadow copies of the country entry. Of course, the specific knowledge attribute allows for this, by flagging which access point is to the master DSA, and which is to a shadow DSA. First Level DSAs therefore have redundancy built into their subordinate references of the root (w/w 9.3).
Fig. 9.3 Knowledge references held by First Level DSAs.
Functional standards groups are placing additional restrictions on the root naming context, by insisting that only subordinate references of the root, and not NSSRs, be allowed. This is a sensible restriction, given the overheads of chaining to a DSA referenced in a NSSR, when it may or may not hold a particular entry, compared with the cost of storing the RDN, which gives a definite indication that the entry exists.
There are two different cases of First Level DSAs to be considered. The first scenario concerns a community that has a single administration which has sole administrative responsibility for the master First Level DSA and the First Level entry. The second scenario concerns a community, such as a deregulated country, where many DSAs want to hold the First Level (country) entry, but in which no single administration has the authority to manage it.
If however the master First Level DSA administration decides to cooperate with another similar First Level DSA administration, then each will configure into their root naming context, a subordinate reference to the other. Users of both communities will then have an identical view of the global DIT, which now, from their perspectives, consists of two communities/First Level entries.
Administrations can continue to create these bilateral agreements with each other. The more bilateral agreements a First Level DSA administration has, the more First Level entries are seen to be connected to the global DIT, by users within that community. If this situation was allowed to develop with the national PTTs, we could have a situation whereby users in different countries would see a different number of other countries connected to the global DIT, this number of other countries being dependent upon the number of bilateral agreements that their own PTT had reached with other PTTs in the world. This clearly is an undesirable situation, and is not conformant to the Standard. One would expect the ITU-T, either to encourage (if not mandate) its members to co-operate multilaterally with each other, or at least to facilitate agreements by establishing an international register of First Level DSAs. (This First Level DSA register would hold the Access Point and the names of the First Level entries that each First Level DSA holds.) A variation of the former route has already been achieved for international telephone services, and so it is not unreasonable to expect a similar scheme to be set up for the Directory. A variation of the latter route is currently being adopted by the North American Directory Forum via its CAN (§ 10.6). However, it is highly likely that during the first few years of operation, different users of X.500, in different countries and in different communities, will initially (if not always) have different views of what the global DIT consists of.
The number of First Level DSAs in one community/country is independent of who administers the master First Level entry. Other DSAs, by arrangement with the master First Level DSA administration, may shadow the master First Level DSA's information, and thus become shadow First Level DSAs. Both the master and shadow First Level DSAs will have identical views of the root context. A shadow First Level DSA may have operational agreements with First Level DSAs in other countries, and may chain requests to and from them. If a shadow First Level DSA does not have an operational agreement with a First Level DSA in another country, then it can always pass the request to its Master First Level DSA for it to continue processing i.e. use the Master First Level DSA as a superior reference, since it knows that the Master First Level DSA does have bilateral agreements with all the other master First Level DSAs. This latter option is not open to shadow First Level DSAs in the following scenario.
It can be seen that there is a difference between holding knowledge references (e.g. the root context) and providing a good quality service to users. A shadow First Level DSA will have subordinate references to all the other First Level entries/DSAs in the world, as provided by its master DSA, but it may have bilateral agreements with none (or only a few) of them. In this case, it might simply return referrals to its customers, that point to those First Level DSAs with which it does not have any bilateral agreements, and let the customers contact the other First Level DSAs themselves. A First Level DSA with many bilateral agreements may offer a chaining service to lots of other countries (First Level DSAs), and thus provide a higher quality of service to its customers. Such is the nature of competition, and the free market.
The North American Directory Forum has taken this model of the procedure that should operate internationally for sharing the root entry/naming context, and applied it to sharing the US and Canada country entries within North America. Thus DSA administrations that wish to have a copy of these country entries, must first inform the NADF which entries (usually organisational entries) they hold below the country entries. (They do not need to tell the NADF what they hold below these organisational entries, although they themselves must know about all of the subordinates of these.) In return they receive details about all the other entries below the US and Canada country entries, as well as the Access Points of the DSAs that hold them.
After this information exchange, in which the Central Administration for the NADF (the CAN) acts as the registration bureau for the NADF, all North American First Level DSAs will hold copies of the US and Canada country entries. They will also have subordinate knowledge references to all the entries below the US and Canada country entries, that they do not hold.
This information exchange procedure could be applied recursively as one moves down the DIT, so allowing an organisation to share the organisational entry amongst a set of DSAs. Each DSA in the set would hold a copy of the organisation's entry, and just some of the subordinates of this entry. However, all the DSAs in the set would have knowledge of the whereabouts of all of the subordinates of the organisational entry.
Should the organisation decide that it wants to communicate with another organisation, resident either in the same country, or in a different one, it merely needs to add a cross reference to that organisation, to its own DSA. The DIT, from its perspective, now consists of just two organisations, and one (or two) countries.
Should the organisation eventually decide that it wishes to join the public global DIT, it will have to contact the administrator of the First Level DSA mastering its country's entry, assuming of course that its name has been nationally registered - see § 9.9.1. A conformant master First Level DSA is required by the Standard to add a subordinate reference to the DSA holding the organisation's entry, and to propagate this knowledge to all shadow First Level DSAs in the country. The organisation's DSA should add an immediate superior reference to the master First Level DSA i.e. a Hierarchical Operational Binding has been created - see § 9.19. Note however that the master First Level DSA is not required to operationally inter-work with the organisation's DSA. This will be the subject of a bilateral agreement in which tariffs etc. are agreed upon. Assuming that such an agreement is reached, the organisation's DSA will add a superior reference pointing to the master First Level DSA, and will then be able to forward Directory requests for entries in the outside world to that First Level DSA. The master First Level DSA will also chain or refer external queries to the organisation's DSA.
If a bilateral agreement is not reached with the master First Level DSA for the country, then the organisation will need to reach an agreement with another First Level DSA operator, and use this as its superior reference, otherwise it will not be able to forward requests everywhere in the outside world. (In this respect any First Level DSA should be able to offer an equivalent service, but the quality of service may vary as outlined in § 9.8.2.) With respect to requests originating from the outside world, the master First Level DSA for the country may not now be prepared to chain requests to the organisation's DSA, but may instead return referrals to the outside callers. The callers will then have to contact the organisation's DSA themselves, perhaps setting up their own bilateral agreements, before adding cross references into their own DSAs. It will be interesting to see how all of this evolves.
In order to guarantee that the organisation's distinguished name is globally unambiguous, it needs to be registered. Most countries are now operating, or creating the framework for the operation of, a national OSI name registration authority. Each authority has the sole responsibility for allocating RDNs at the appropriate place under its DIT country node. The appropriate place will be determined by the regional standing of the organisation. An organisation of national standing will be registered under the country node, an organisation of local standing will be registered under a locality node below the country. Organisations should therefore contact their national name registration authority in order to determine how best to register their preferred RDN. Coupling the registered RDN with the stub provided by the registration authority (e.g. {C=US, ST=Florida}) gives the organisation its distinguished name. Failure to register its RDN may preclude an organisation from joining the public global DIT without first changing its distinguished name. This is because it may find that some other organisation has already chosen, registered and is using the same name. It would then need to choose and register a different name, and rename all of its local DIT entries before it could join the global DIT. Obviously the global DIT cannot accommodate two organisations with the same distinguished name.
Within the UK, a British Standard [8.1], defines how UK organisations are to be named. Two alternative methods are defined. For those companies who are nationally registered under the Companies Act 1985, the relative distinguished name of the organisation may be that of the registered company name. For example, XYZ Plc, can have a relative distinguished name of {O=XYZ Plc} and a distinguished name of {C=GB, O=XYZ Plc}. For charities, educational institutions, and any organisation that so wishes, BSI [8.2] offers a name registration scheme whereby, for the fee of £150 + VAT (1992 price), an organisation can choose any relative distinguished name that is reasonable. This may then be registered under either the country node, or one of more than a hundred locality nodes. Registered companies may use this route to register alias names and shortened versions of their official company name. A mechanism is defined to resolve contentions, but as with any scheme, such as the registration of trade marks, it is on a first come - first served basis. (An object identifier (Appendix A) can also be obtained at the same time for no extra charge, but an X.400 ADMD name will cost an additional £300 + VAT (1992 price).)
The US (ANSI) has adopted a similar scheme to the UK, but prefers that organisations register at the state level rather than at the national level. Organisations are encouraged to follow this route, since punitive charges are levied for national registration. Organisations should therefore register their preferred RDN in all of the States of the Union.
Therefore if a company has long term strategic plans to migrate to X.500,
then they should register their organisation's name as soon as possible.
{kind=link}
{kind=link}
{kind=link}